

Many folks have asked questions regarding what is an optimized way to set up Bazel in CI. In particular, how to go about organizing and operating your CI Workers.
Although I have hinted toward what is an ideal setup over in the Bazel Cache Explain series, I have never explicitly suggested any design/architecture go about hosting Bazel-optimized CI workers.
So let's talk about these CI Worker setups today.
1. Ephemeral Workers
Getting started, most organizations and companies would want to use Ephemeral CI Worker. This is because they are easier to set up.
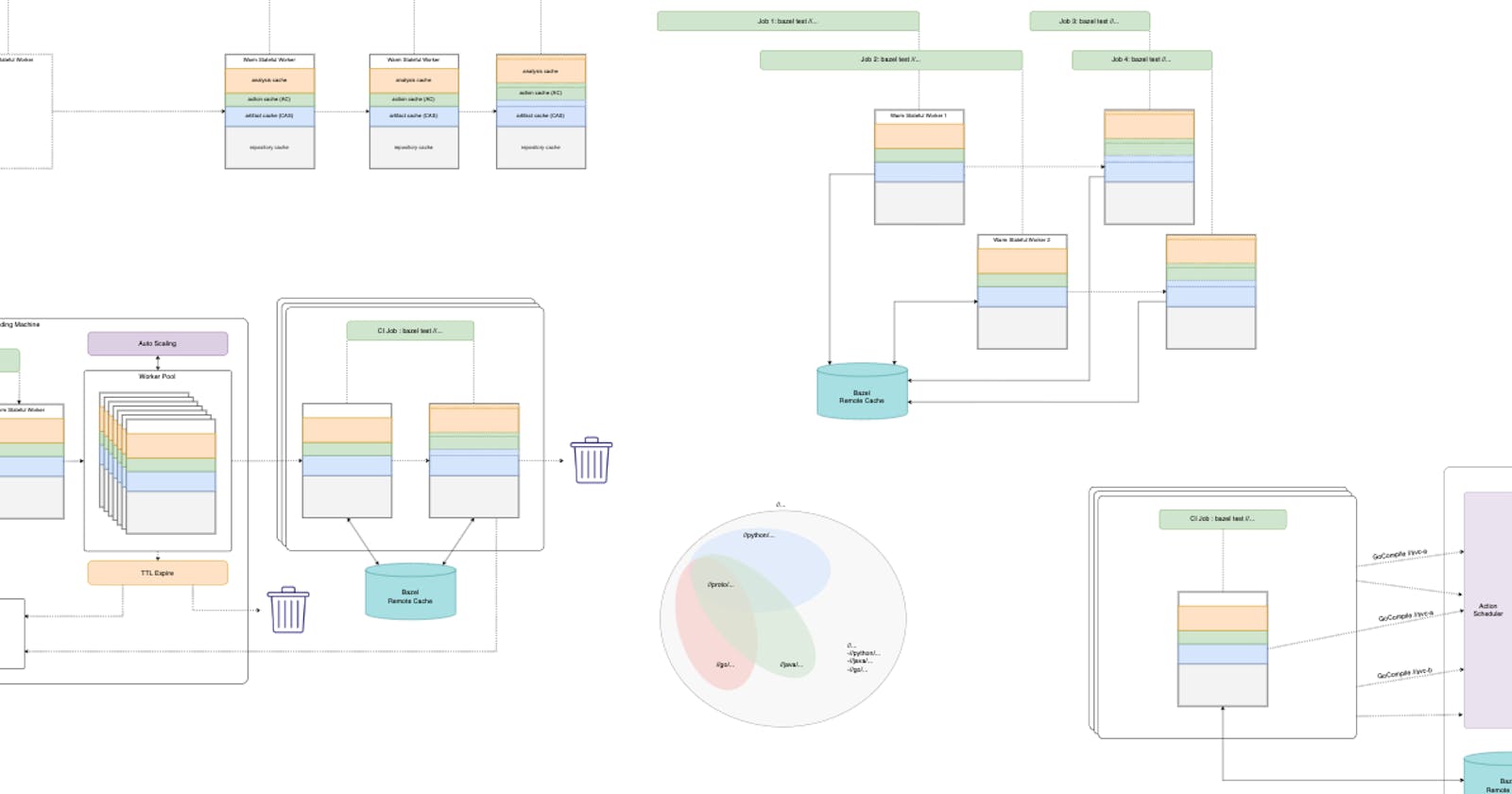
Most CI vendors support some sort of Ephemeral CI Sandboxing solution out of the box. Most likely, they would allow you to run some shell commands in a Docker Container / VM somewhere.
Among those shell commands, you could insert a bazel test //... call somewhere to trigger the Bazel build.
However, due to the ephemeral nature of this setup, you would have to recreate the Bazel JVM server every time, discarding the in-memory cache that Bazel often depends upon.
Furthermore, ephemeral environments also discard the Local Persistent Cache, forcing every Bazel builds to re-run from scratch.
A more expert user would look into pointing --disk_cache into a re-useable container volume mount.
This should help reduce the action executions thanks to the CAS and AC being cached locally on disk.
Additionally, pointing --repository_cache to a similar volume mount should also help reduce external dependencies downloads. I wrote about Bazel Repository Cache in detail here.
However, your build should still be relatively slow as the analysis phase would still require running from scratch every time. Many repository rules actions still need to be executed on top of the downloaded archives in Repository Cache.
2. Single Stateful Worker
As your monorepo gets bigger, it will eventually outgrow the Ephemeral Worker CI setup.
Builds and tests get slower as the Analysis phase grows with the monorepo complexity. More actions and more artifacts translate to more nodes and edges in the build graph and traversing them all takes time.
Previously, the way we sped up Ephemeral Worker is to reduce the ephemerality of the setup, enabling isolated local caching through usages of Disk Cache and Repository Cache.
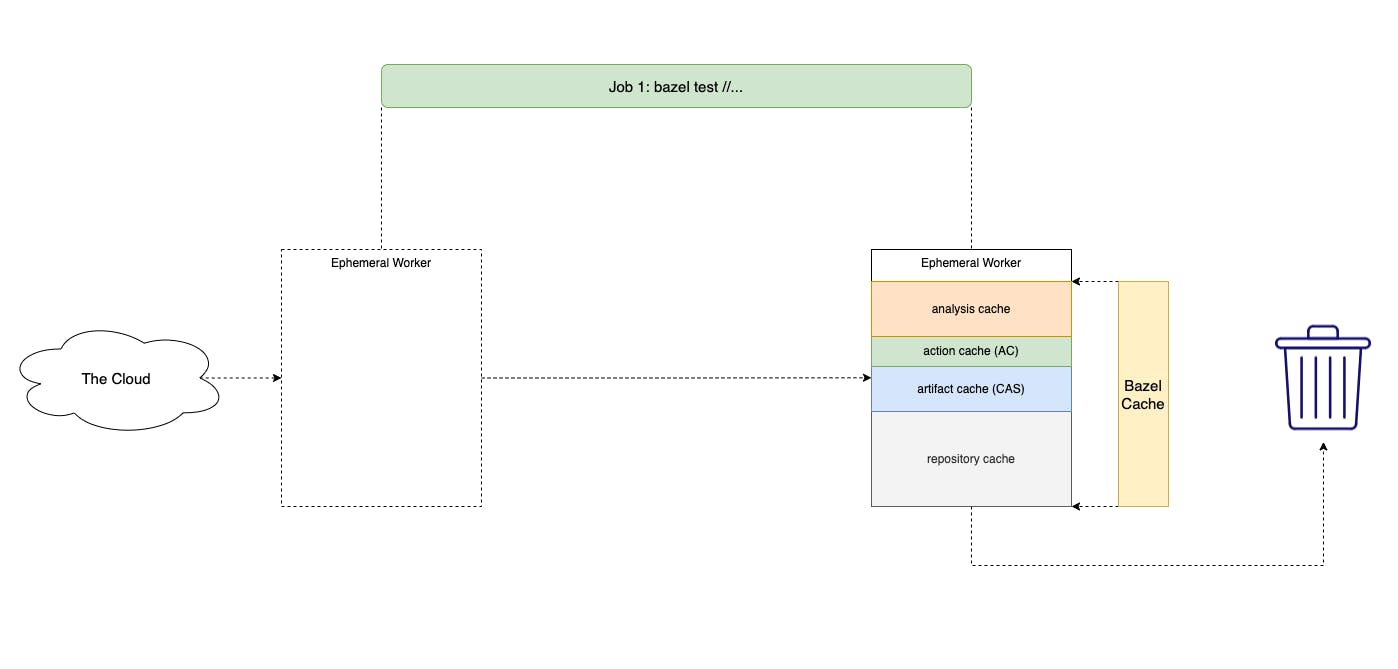
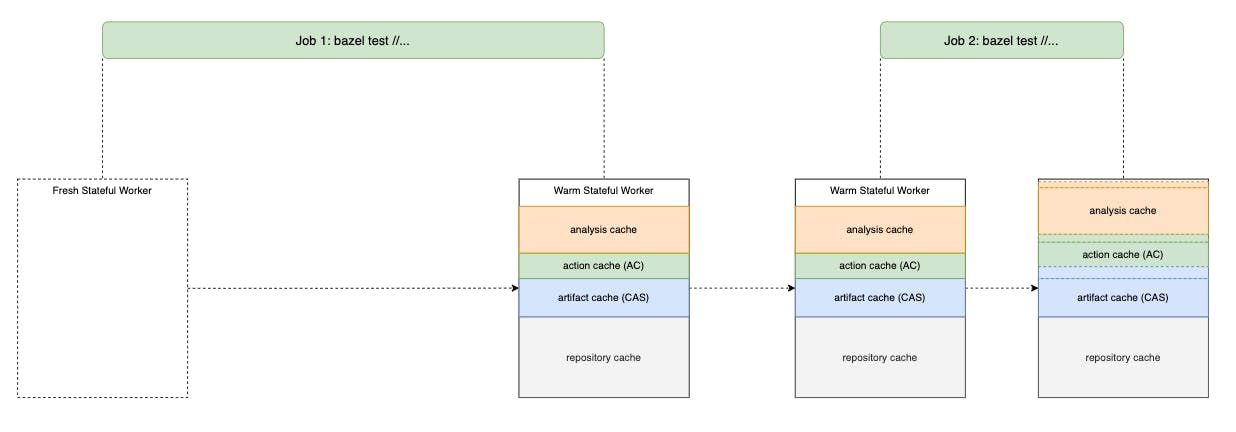
Following that theme, to speed up Bazel's Analysis Phase, we want to leverage Bazel's in-memory cache. By re-using the same Bazel JVM between CI jobs, we could save a lot of time running Analysis Phase over and over again.
A trick here is to also enable --watchfs, enabling the Bazel JVM to capture changes to the project using fsnotify instead of having to stat() and hash all the files in the project over and over.
Enabling stateful workers would require some additional attention though.
First, the CI sandbox technology could no longer be a container. To keep the JVM process alive between jobs, you must re-use the same container / VM, thus the CI unit-of-isolation needs to be a shell session.
However, this massively reduces... the isolation of your CI environments (Duh!). Some of the new risk vectors would include:
- Disk out of space
- Git lock files not being cleaned up between jobs
- Dirty files being used in builds
To combat these, you would want to create a wrapper to handle such cases before and after Bazel execution, thus, increasing the complexity of your CI setup.
By using a single stateful worker, you would want a mechanism to seed a fresh worker with some states before picking up a CI job. A new worker provisioning process, such as using terraform to create a VM instance, should include some "cache seeding" logic so that we could ensure the worker would only pick up jobs with some warm local cache. This could be as simple as performing a single Bazel build from the latest default branch of the project.
One would think that using a stateful worker would increase the cost of infra to the business. In my experience, the opposite is true: by being able to perform builds and tests faster, we were able to scale down in total compute needed. Not only that we pay less for infra, but our engineers also became more productive overall thanks to a faster feedback cycle.
The increase in CI setup complexity does increase the overall cost of ownership, so there is a tradeoff to be made. Moving forward, this will become a more common theme: by increasing the CI complexity setup and investing in the right solutions, we manage to save infrastructure costs and help other engineers be more productive.
3. Multiple Stateful Workers
As your team grows larger, the frequency of changes increases. A single stateful worker would no longer cut it. P50 of build-in-queue and queue time should be some of the prime indicators when this happens.
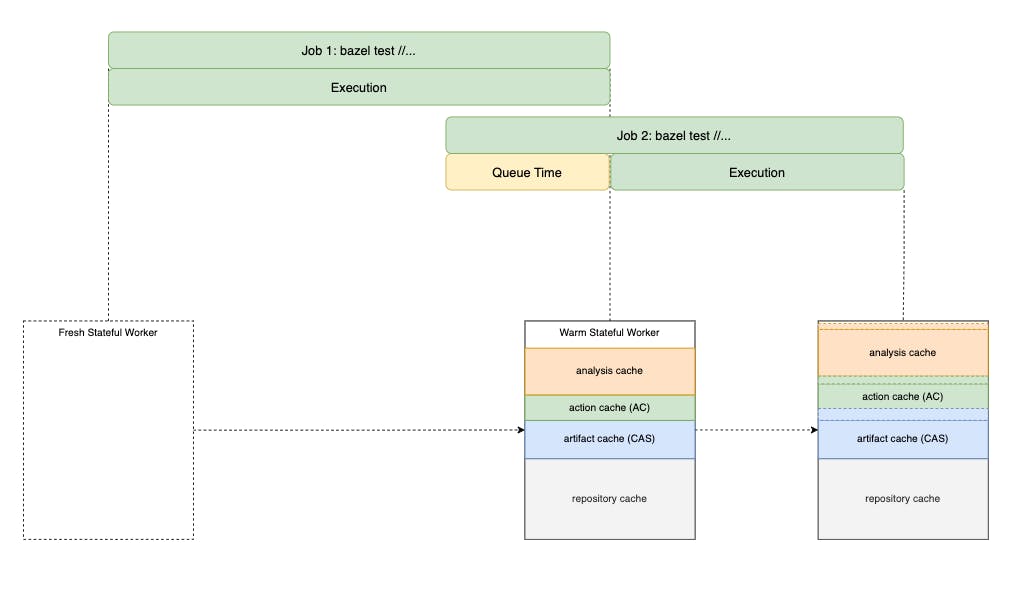
These are vital signs that you would want to set up more than one stateful worker.
However, a multiple stateful workers setup comes with new challenges. As these contain states, you are facing the obvious set of CAP-theorem class of problems:
Multi-workers means that the workload will be distributed thus decreasing the queue time overall, and more workers are available to pick up new jobs. However, the local cache content will be inconsistent between workers, the more workers you have, the less consistent they are.
This could lead to tests and builds needing to be rerun multiple times across different workers. Thus there should be an overall increase in build/test time as more workers are added.
To address the consistency problem in this setup, you would want to leverage --remote_cache to centralize all CAS and AC results in shared storage between workers. Being able to look up pre-existing action entries inside the Action Cache, workers should be able to avoid re-compiling and re-running tests when the same job is re-executed on a different worker.
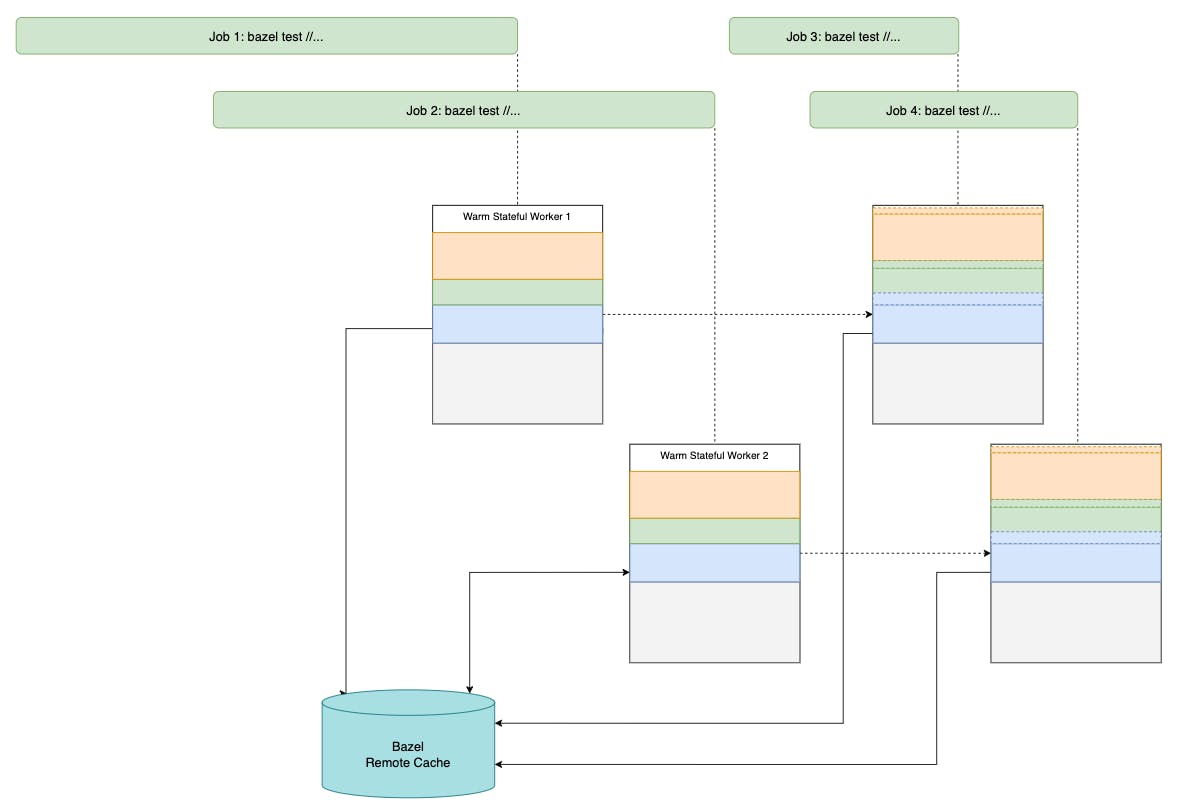
Furthermore, you would want to look at enabling Merged Result CI builds. This version control strategy should help ensure local cache across different workers keep moving forward with the default branch of the project. As the CI jobs are run using a common base branch, CI workers could use the CAS and AC of that base branch to keep the local cache consistent over time.
A common foot gun when implementing Multiple Stateful Workers is provisioning more workers than you would need. More workers mean the local cache on each worker becomes more sparsely distributed, thus reducing the overall local cache hit rates. At scale, even fetching cache from a centralized Remote Cache instance could come at a serious price.
To combat this, I would recommend keeping the total worker count just low enough to keep your CI Job queue time under 30 seconds. Also, provide a regular schedule maintenance task that would take inactive workers out of the pool during downtime and replace it with fresh workers and the latest cache seeded locally.
4. Worker Vending Machine
As the monorepo grows larger, the number of issues related to CI isolation should increase. From git networking failure left over some lock files which could fail the build, to local cache poisoning from 1 build affecting subsequent builds. By monitoring and classifying different classes of failures observed in CI, you should be able to tell how much benefit having a sanitized testing environment would be for your setup.
Another class of problems that you would often encounter is how to scale up the throughput of your Bazel Remote Cache solution. By having multiple workers, the local cache could be highly fragmented and distributed between workers. This could result in highly inconsistent download content between these workers and Bazel Remote Cache. If your Remote Cache is set up on a multi-tier storage medium: In-Memory, Local Disk, and Remote Object Storage, then these irregular downloads would make it hard to consistently keep a hot set of cache entries within the faster cache tier. As a result, you should be able to observe higher network throughputs, and more frequent cache tier promotion/demotion which causes higher Remote Cache download speed overall.
To combat all these issues, we would want to make our workers operate more uniformly, even between different CI Jobs. A well-known design for this is a CI Worker Vending machine.
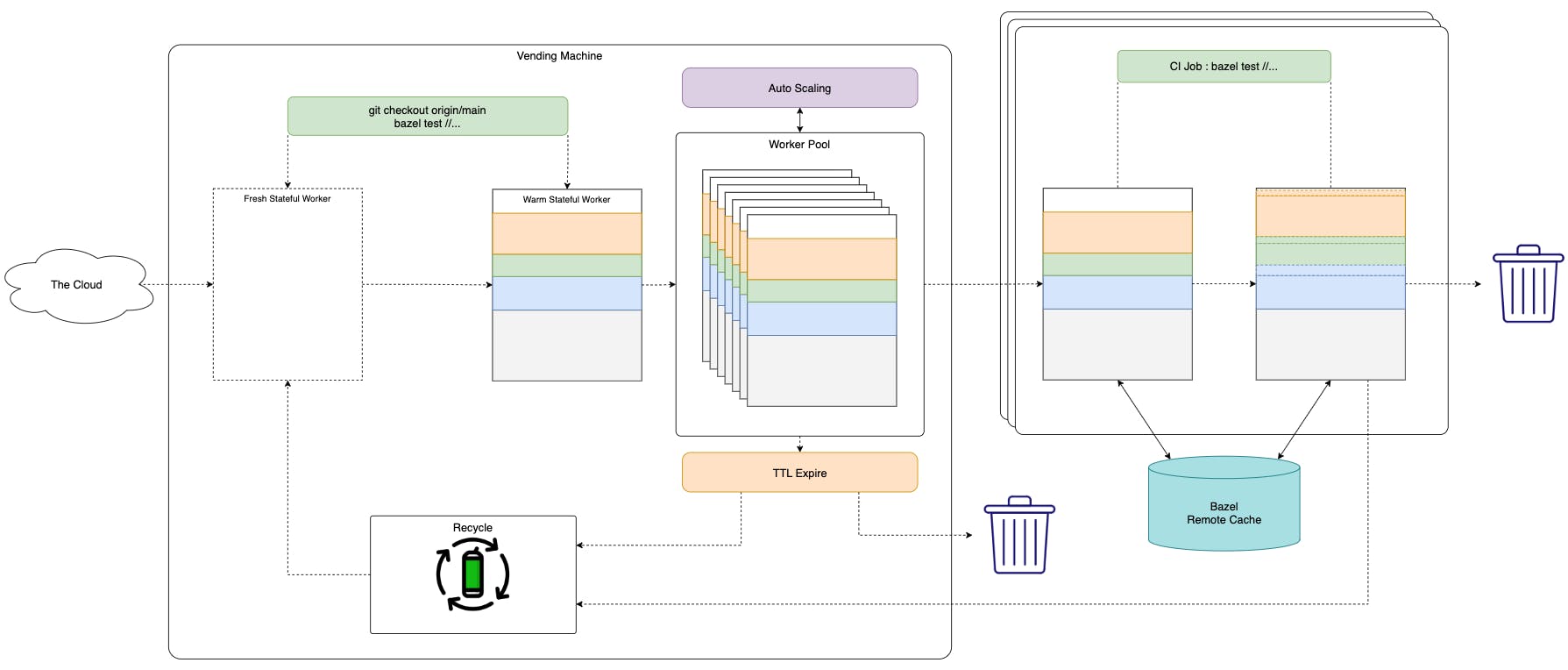
Vending Machine is a service that managed a hot pool of workers, ready to dispatch to serve incoming CI Jobs. After finishing serving a CI job, the worker could be returned to the pool after going through some cleanup recycling processes of the Vending Machine, or simply get discarded while the Vending Machine prepares new hot workers. The decision to recycle workers or not often depends on how easy is it to provision and warm up a new worker: on-prem infra vs cloud infra, or different VM solutions come with different startup speeds.
Idle workers in the pool are subjected to a certain Time To Live(TTL). If the TTL has passed and a worker still has yet to pick up a job, the unused worker is deemed to be cold and subjected to similar recycling logic as a used worker.
Under such a setup, we could accomplish a higher degree of ephemerality for each worker serving a new CI Job, while maintaining the benefits of using a hot worker with all the needed cache pre-warmed locally.
Custom auto-scaling logic could be applied to the Vending Machine service to help reduce computing costs. Some newer technology such as FireCracker MicroVM is highly suitable for this setup thanks to lower startup time and the ability to resume a VM with Bazel In-Memory Cache in place.
5. Sharded Worker Sets
As your build graph grows, you should start to see how Bazel Analysis Cache grows larger, thus demanding more memory from the Bazel JVM. At this scale, you should start to see Bazel JVM being OOM killed regularly during the Loading-and-Analysis phase.
There is no definitive solution for this class of problem today, at least not to my knowledge. Ideally, there should be a way for Bazel JVM to offload these analysis cache remotely, either serialize the cache entry to some on-disk file format or provide a way to store these cache entries in a horizontally scaled remote cache. Unfortunately (or fortunately), not a lot of projects managed to reach this scale for this to be a relevant enough problem. Most projects today could still get away with vertically scaling up the Bazel worker.
But what if you are one of the rare projects that manage to hit this scale? Or if you have difficulty scaling up CI workers vertically because replacing bare-metal servers could be a time-consuming challenge?
Sharded Worker Sets are niche mitigation that could help.
The theory behind Sharded Worker Sets is fairly simple
# Given a CI setup like this
> bazel test -- //...
# We should be able to achieve similar results by running 2 smaller builds
> bazel test -- //service-a/...
> bazel test -- //... -//service-a/...
Visually, we could divide our "build everything" setup into a set of multiple builds, each with smaller target patterns resulting in a smaller Analysis Cache. In practice, this should look something like this:
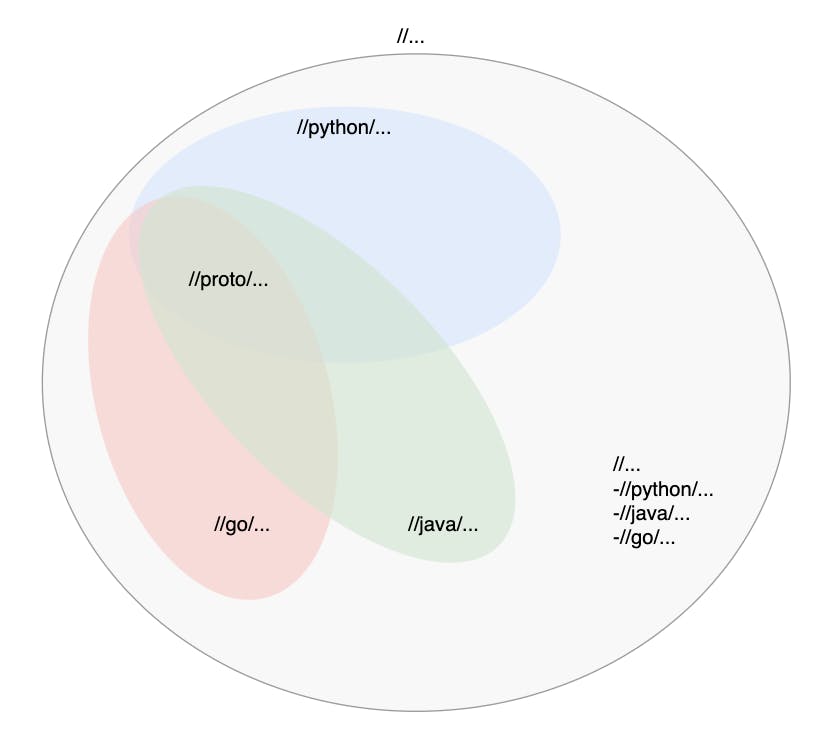
We need to create a dedicated set of CI Worker pools for each unique set of build targets used to avoid Bazel discarding the Analysis Cache when switching target patterns. This would result in the following:
- A dedicated pool of CI workers for
//python/... - A dedicated pool of CI workers for
//java/... - A dedicated pool of CI workers for
//go/... - A dedicated pool of CI workers for the rest,
//... -//python/... -//java/... -//go/...
The good thing about this profile-based sharding process is that it could be done incrementally. Most of the complexity of managing a new set of CI workers should have already been solved at this stage so adding X more pools should not come with a significant cost for the Build / DevX team who own them.
6. Remote Build Execution
Another side effect of sharding your build is now your build and test actions are now executed on multiple workers instead of a single worker. This should allow us to achieve higher execution parallelism as builds are now executed with more computing.
However, a large portion of these actions is duplicated. First, each action might not yet exist on the Remote Action Cache. Two workers may then execute the same action if the overlapping time between action scheduling is small enough.
Secondly, there is a large action overlap between the set of targets if there are common dependencies between the 2.
For example, both //go/... and //java/... could have a shared //proto/... dependency.
This could easily result in actions needed to build //proto/... being executed twice on different CI workers.
To better help with action scheduling and deduplication, a Remote Build Execution (RBE) solution could be used.
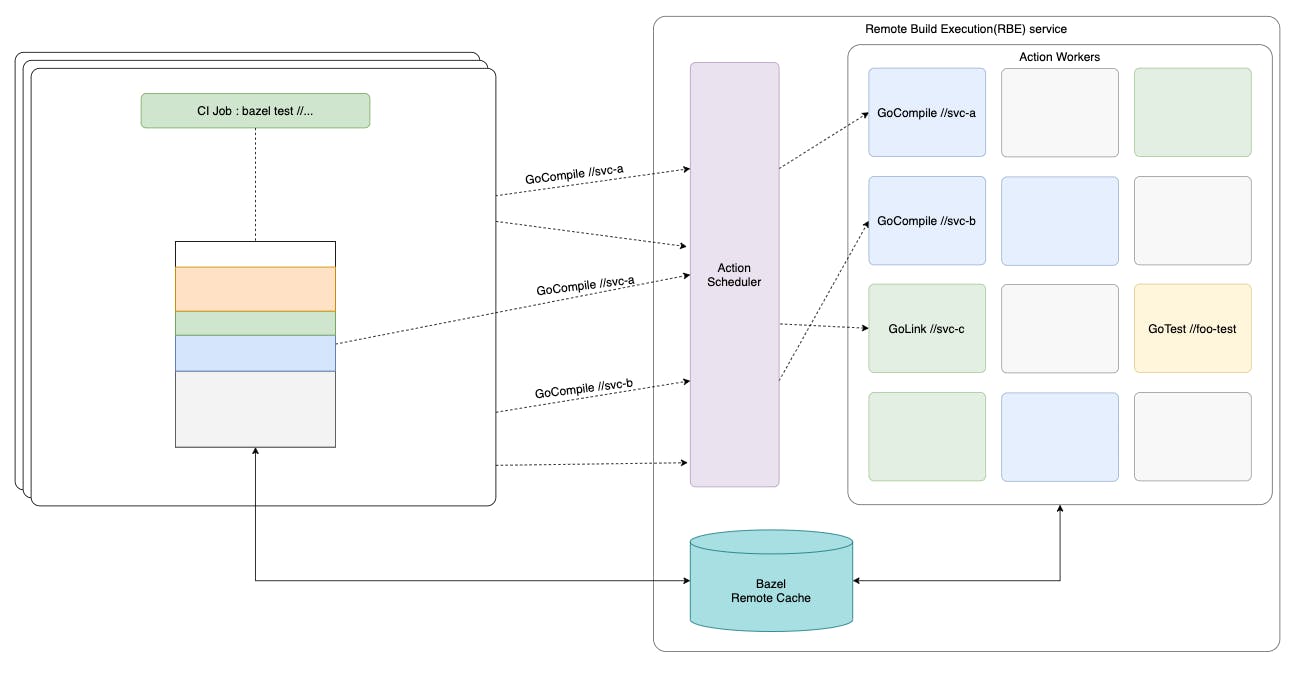
RBE solutions often come with deduplication in action scheduling. Multiple CI workers requesting RBE Scheduler to execute the same action will result in a single execution. The result of said execution will be returned to the CI workers subsequently. Here is a blog post from folks at Stripe implementing the same solution.
 (Image from Stripe's Blog)
(Image from Stripe's Blog)
In practice, RBE is a powerful solution for you to massively parallelize the execution of your build graph and your tests at a very efficient computing cost. Operating an RBE solution, however, is not a small feat. Some sufficiently scaled solutions could easily double if not triple the cost of ownership for your CI setup over time. Although the lure of resource efficiency is very appealing to deploying an RBE setup, there is a tradeoff for operation complexity that is worth some thought.
Unlike the Sharded Worker Sets solution, with RBE, not only that we need to increase the amount of computing needed for the setup, but we also increased the number of unique components that a team would need to own and manage over time. For this reason, SaaS solutions for RBE are generally very well suited for enterprise organizations. The downside here is usually a lack of customizations and integrations that is tailor-made for your engineering workflow.
Conclusion
Above, we discussed different ways of setting up CI Workers to handle Bazel's workload. With each setup comes a certain set of tradeoffs:
- Isolation vs Reusability
- Operation Complexity vs Scalability
In reality, you don't necessarily need to follow this exact order of adoption. Instead, measure and choose what is right for your monorepo and your team. These improvements could be done incrementally, as each of them is targeted to solve a different set of problems of your build. So don't rush into something that you are not gonna need. Measure, identify bottlenecks, and apply the right solution for the right problem.
Finally, I have seen some organizations jumping straight from Ephemeral CI Workers to Remote Build Execution with great success. Much thanks to the increase in commercial RBE solutions in recent years. These solutions help reduce the overall cost of ownership for organizations that are adopting Bazel today. No longer do you need to target hire for a specialized engineering team to manage your custom Action Worker pool, which could easily take 6-12 months of different HR recruitment processes. The cost of adopting Bazel overall has been reducing and that's a wonderful thing 🙌