Bazel Caching Explained (pt. 1): How Bazel Works
A recap of how Bazel builds and tests a project.

I'm Son Luong Ngoc, a Solution Engineer at BuildBuddy. Previously I worked at Qarik / Booking.com / Lazada / Alibaba.
I am passionate about Developer Experience and the Reliability Culture in software development.
Before we dive into Bazel’s caching mechanism, let’s first go over how Bazel works and some of the underlying assumptions that it makes.
The Build Graph
Bazel is an artifact-first Build Tools. This means the user asks Bazel for an artifact and Bazel will execute various different actions in order to provide the targeted artifacts to the user.
In other words, the basic building blocks of Bazel are composed of artifacts and actions which consume and produce those artifacts.
Here is an example on how this would work with a Golang project:
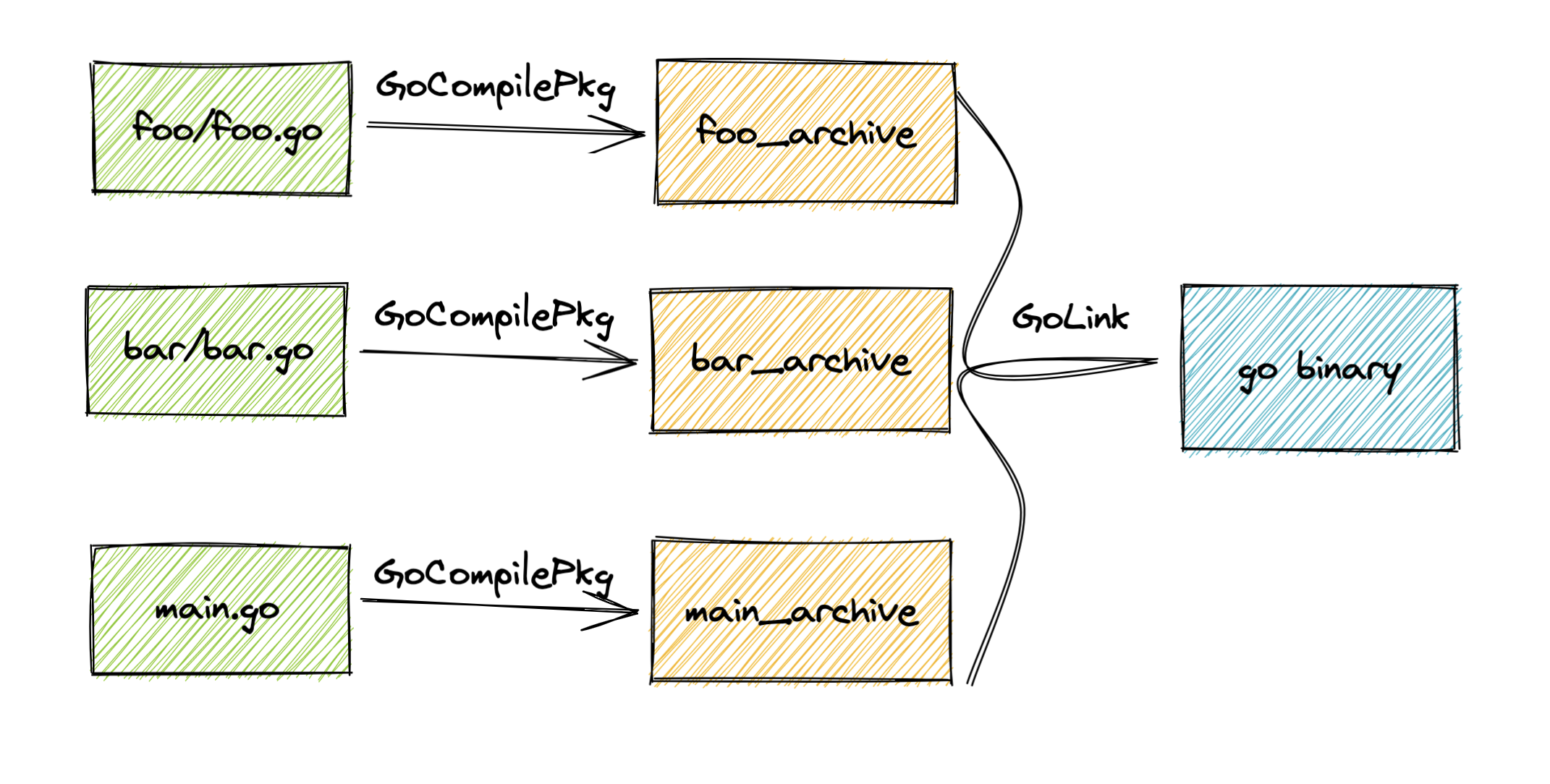
In the picture above, each rectangle represents an artifact and each arrow represents an action. An artifact could be any blob file that is currently presented in your workspace (source code, git LFS) or externally downloaded dependencies. An artifact could also be intermediary generated files, like the main_archive or bar_archive shown above. An action may consume one or multiple artifacts and must produce at least one artifact.
Users interact with Bazel often by telling it what they want it to produce at the end.
I.e. bazel build //:go_binary tells bazel to produce the final go_binary artifact.
Bazel will then parse up the current workspace configuration and construct a graph of artifacts and actions.
Then reverse engineers from the required target //:go_binary to the required actions: GoLink → go_binary.
Then reverse engineers from the actions to the required input artifacts: foo_archive + bar_archive + main_archive → GoLink → go_binary.
The reverse engineering continues until Bazel has finally got to all the artifacts it currently has in the workspace. At the end, we will have a queue of actions with expected inputs and outputs:
foo/foo.go→GoCompilePkg→foo_archivebar/bar.go→GoCompilePkg→bar_archivemain.go→CompilePkg→main_archive- (
foo_archive+bar_archive+main_archive) →GoLink→go_binary
These actions will then be queued up to a scheduler to try its best to execute these actions in parallel.

This network of artifacts and actions dependencies is also known as the Build Graph in Bazel. In real project, this graph could be expansive and have thousands of nodes with various types of rules and actions and in-between artifacts.
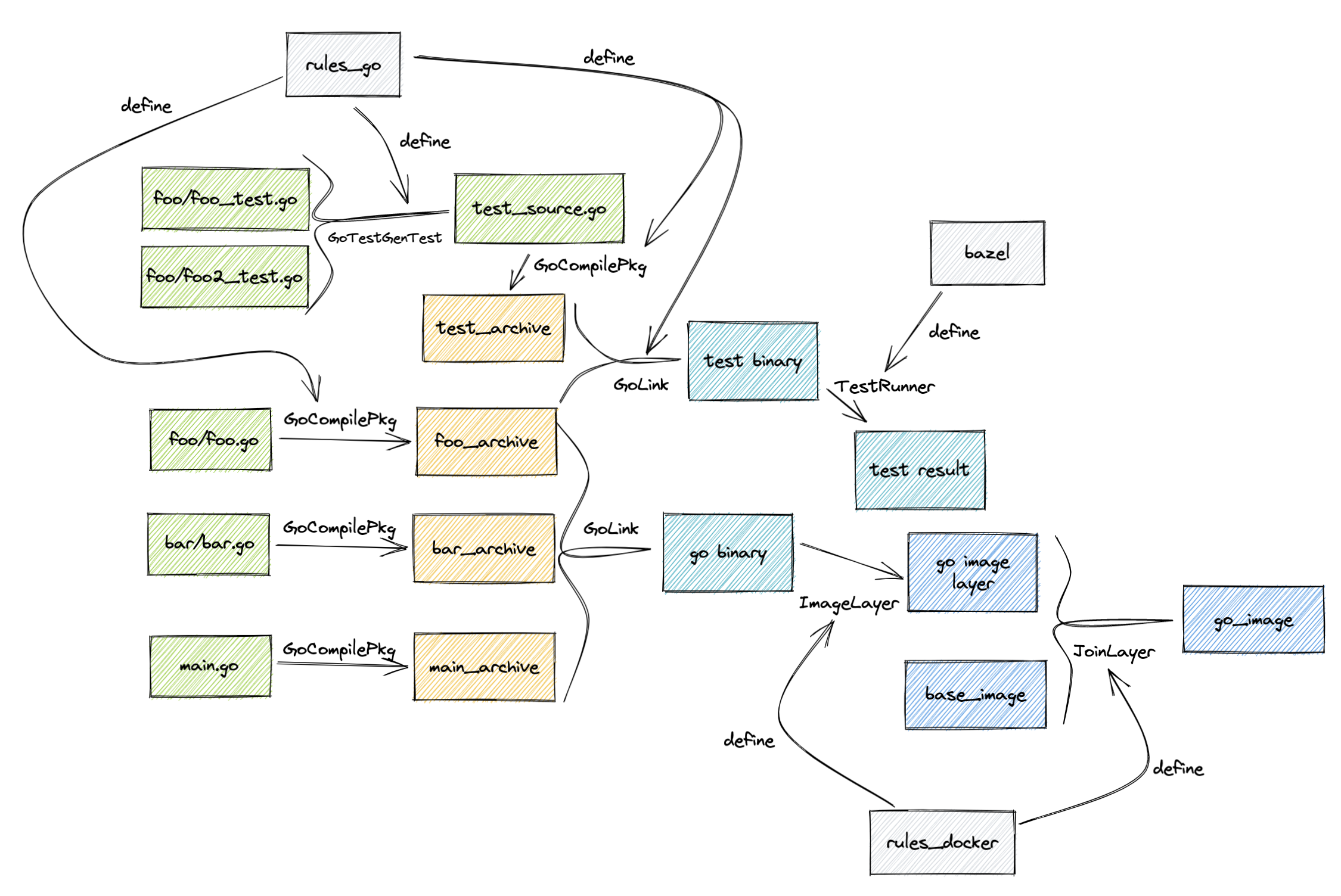
Assume Hermetic Action
Bazel operates under the assumption that every actions in the Build Graph is hermetic. That means given a set of inputs and an action A consuming those inputs, we should always get a fixed set of deterministic outputs, regardless of how many times we execute action A.
Let’s examine some examples of what is a hermetic action and what is not.
Creating a file from template
bash_script_template = “”” #!/bin/bash echo “hello {user}” “”” content = bash_script_template.format(user=config_user_name) os.write(“my_script.sh”, content)This is a hermetic action because given a fixed config input config_user_name. It would always produce a
my_script.shfile with exact same content.Concatenate 2 files
file1 = input[0] file2 = input[1] content = os.exec(“cat {f1} {f2}”.format(f1=file1, f2=file2)) os.write(“output_file”, content)This is a hermetic action as well. Because given a set of
file1andfile2, we will always produce anoutput_filewith the same content.Network call
#!/bin/bash curl -sL ‘https://my-awesome-host.com/download/library.tar.gz’ -o out_lib.tar.gzThis is a non-hermetic action that takes no input and produces an output based on external dependency. The content of the external dependency could change unexpectedly:
- Being replaced with a newer version
- Network being unreliable resulting in error responses
- Thus the action would not have a deterministic output to be hermetic.
Datetime
#!/bin/bash datetime > out.txtDespite having no input, this is a non-hermetic action. The output changes every time this action is executed.
Randomization
#!/bin/bash echo $((RANDOM % 100)) > out.txt echo $((RANDOM % 100)) >> out.txt echo $((RANDOM % 100)) >> out.txtThis is a non-hermetic action. The output changes every time this action is executed.
In some special cases such as test actions, Bazel would provide a fixed random seed for action to consume.
Actions could use the fixed random seed to produce a fixed set of random results, therefore, turning action into a hermetic action.
CAS and AC
The assumption that all actions are hermetic enables us to execute each action only once. In subsequent invocation of the same action, instead of executing it, we simply reuse the old outputs.
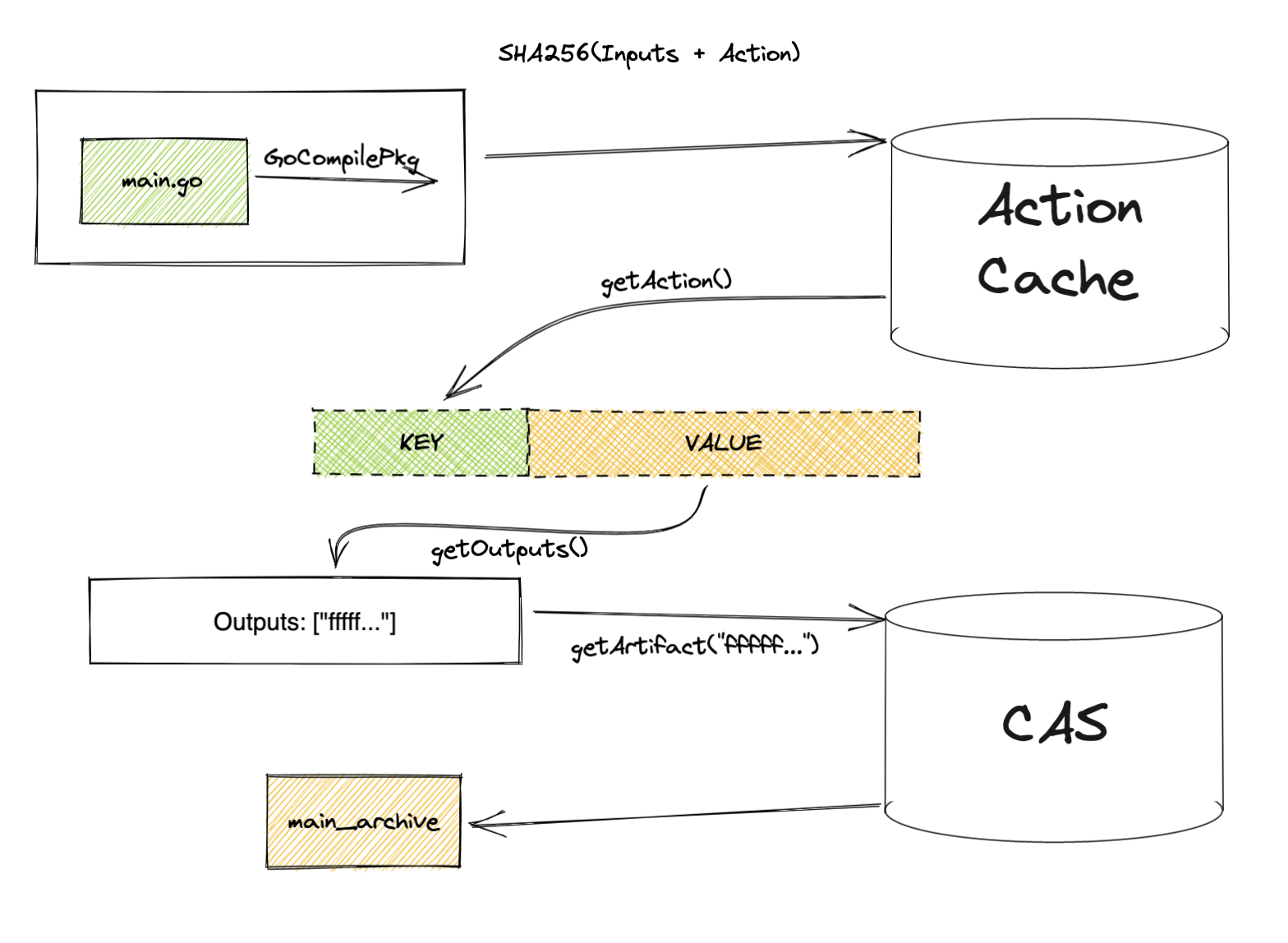
To acomplish this, Bazel treats each of the artifacts, input or output, as a blob (generic binary file). A blob will get its content hashed by a strong cryptographic algorithm (SHA256), resulting in a hash key that is unique to the file’s content.
The artifact blob will then get stored under a directory where the path is made up of the hash key. This allows Bazel to later look up the artifact content to use it using a known hash value. This means that you can retrieve each action’s old outputs from this file cache, instead of executing the actions, if we know the outputs’ hashes beforehand. This blob cache store is also known in Bazel as the Content Addressable Store or CAS for short.
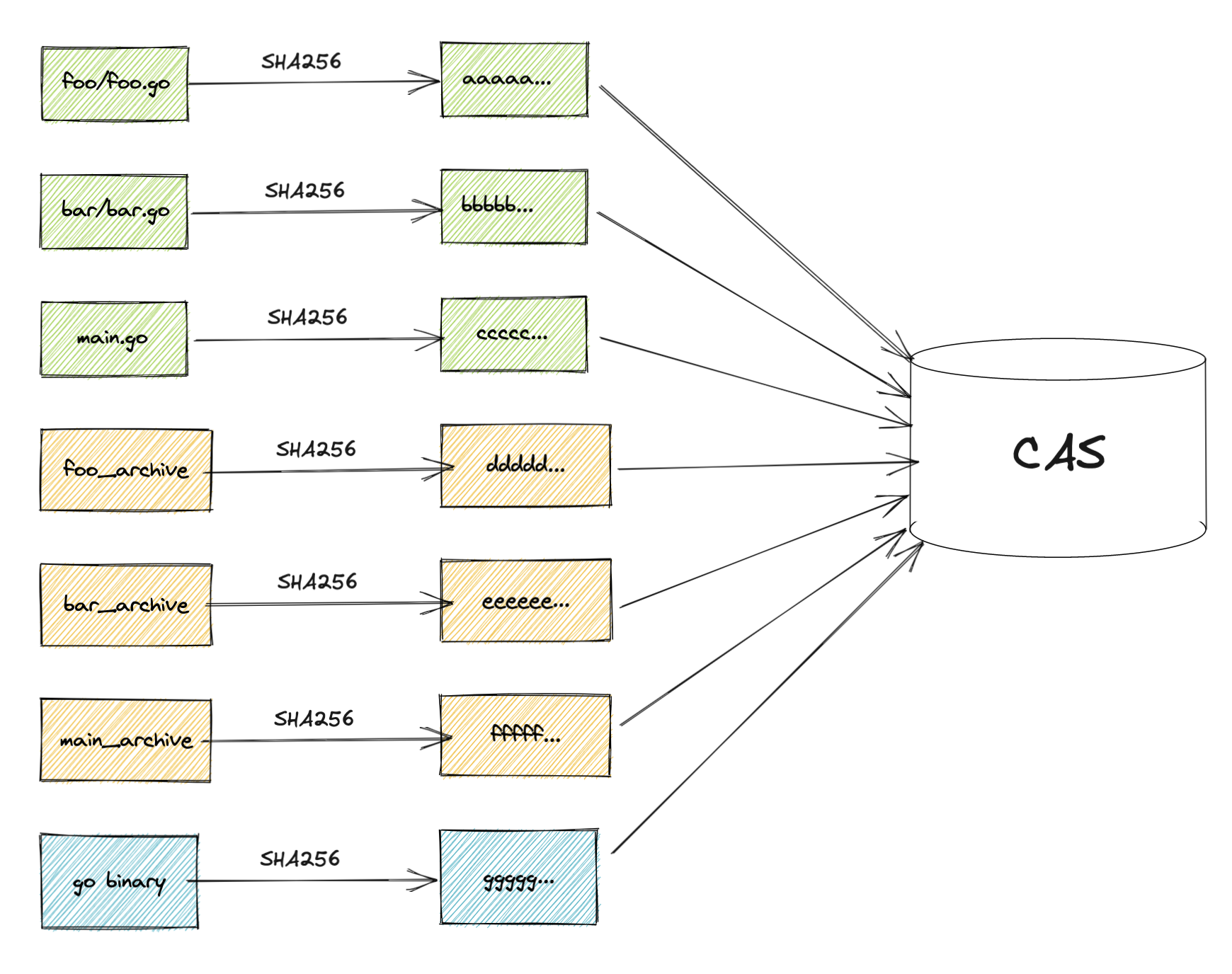
But how do you know the output hashes beforehand?
Assuming the actions are hermetic, then we would just need to execute each action once and cache the hashes of the outputs.
But what would be the cache key for this? How should this be updated when the inputs are updated?
In Bazel, actions are represented in a protobuf composed of different elements.
You can use Bazel's Action Query, aka. bazel aquery, to explore how these actions are formed.
Here is a minimal example:
> cat BUILD.bazel
genrule(
name = "a",
outs = ["a.txt"],
cmd = """
touch $@
""",
)
> bazel aquery //...
action 'Executing genrule //:a'
Mnemonic: Genrule
Target: //:a
Configuration: darwin_arm64-fastbuild
Execution platform: @local_config_platform//:host
ActionKey: 2f44a537c2e4f4b6a3386b81f69f56e06d0755078353dcfc9b4831b85b92037f
Inputs: [external/bazel_tools/tools/genrule/genrule-setup.sh]
Outputs: [bazel-out/darwin_arm64-fastbuild/bin/a.txt]
Command Line: (exec /bin/bash \
-c \
'source external/bazel_tools/tools/genrule/genrule-setup.sh;
touch bazel-out/darwin_arm64-fastbuild/bin/a.txt
')
This action metadata, including the inputs and action's definition, will then get hashed. This hash will be used as the cache key for future look up. The cache value not only also includes the inputs and action's definition, but also the hashes and names of the outputs. These key-value will then be stored in a different cache store called Action Cache aka. AC. Note that this is different from CAS as the cache key is only the hash of part of the cache value: we did not include the outputs in the hash calculation. This allows us to look up the outputs in the value while knowing only the inputs and action's definition.
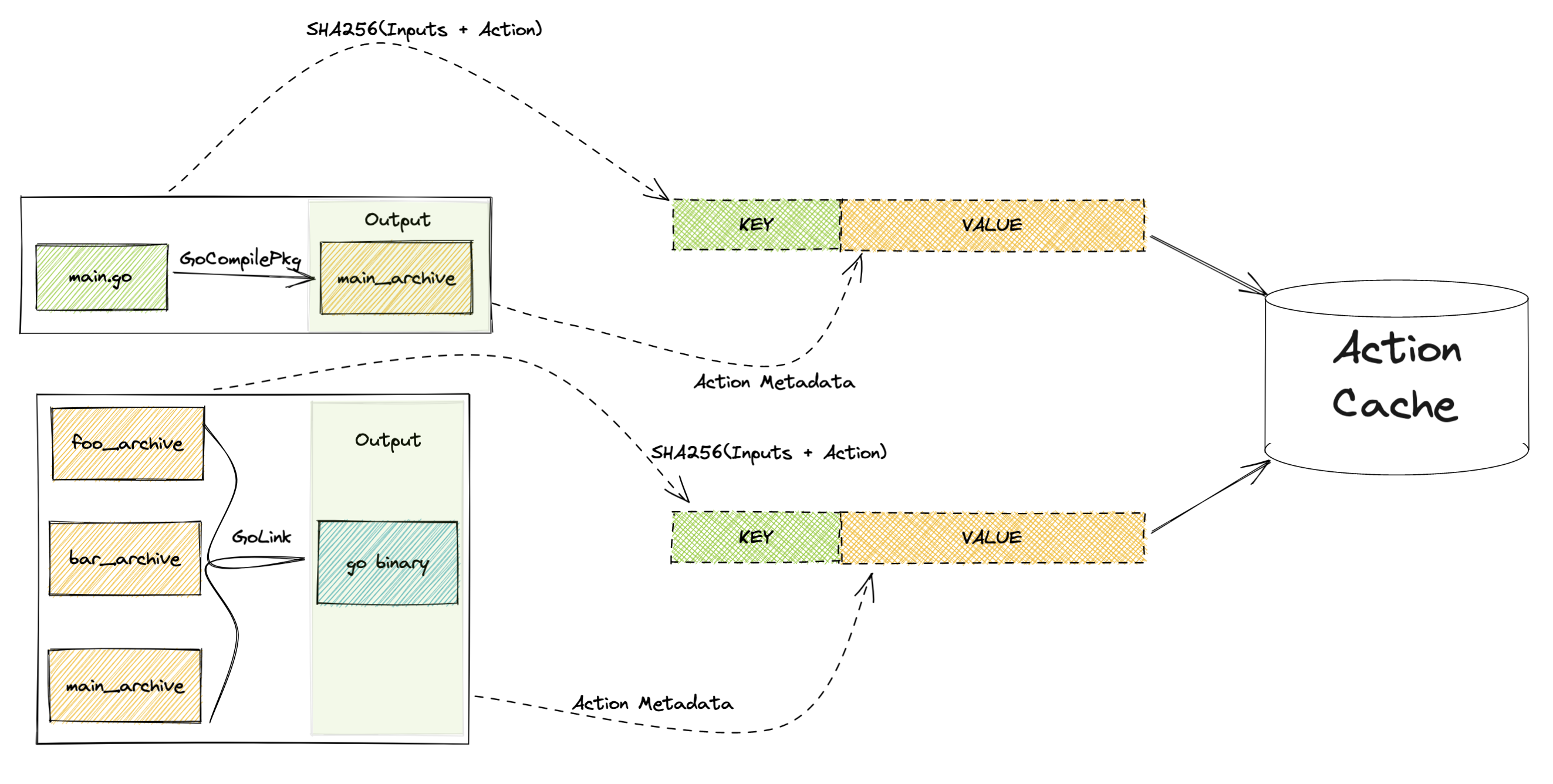
On subsequent invocation of this action, the input artifacts’ hashes and action’s definition will be used to form a similar action protobuf. Then, before executing the action, bazel will try to look up the action outputs’ hashes as recorded in AC.
If the outputs’ hashes are found in AC and the output could be found in CAS using said hashes. Then Bazel would skip out on executing the action.
Otherwise, the action is executed, the outputs are stored in CAS and action metadata is stored in AC for future re-use.
More technical readers would have realized that this whole Build Graph is, in fact, a Merkle Tree and that would be correct. Bazel makes extensive use of Merkle Tree data model, not only to de-duplicate data storage, but also to cache artifacts as well as actions’ execution results to save on execution time.
Some other technologies where Merkle Tree is also used: Git, Mercurial, Block Chain, ZFS, Cassandra.
Reference: https://en.wikipedia.org/wiki/Merkle_tree
Cache Invalidation
Now that you have been familiar with how Bazel operates generally, let’s do a small exercise:
What would happen to this Build Graph when the user were to update “main.go” source file? And in what order?
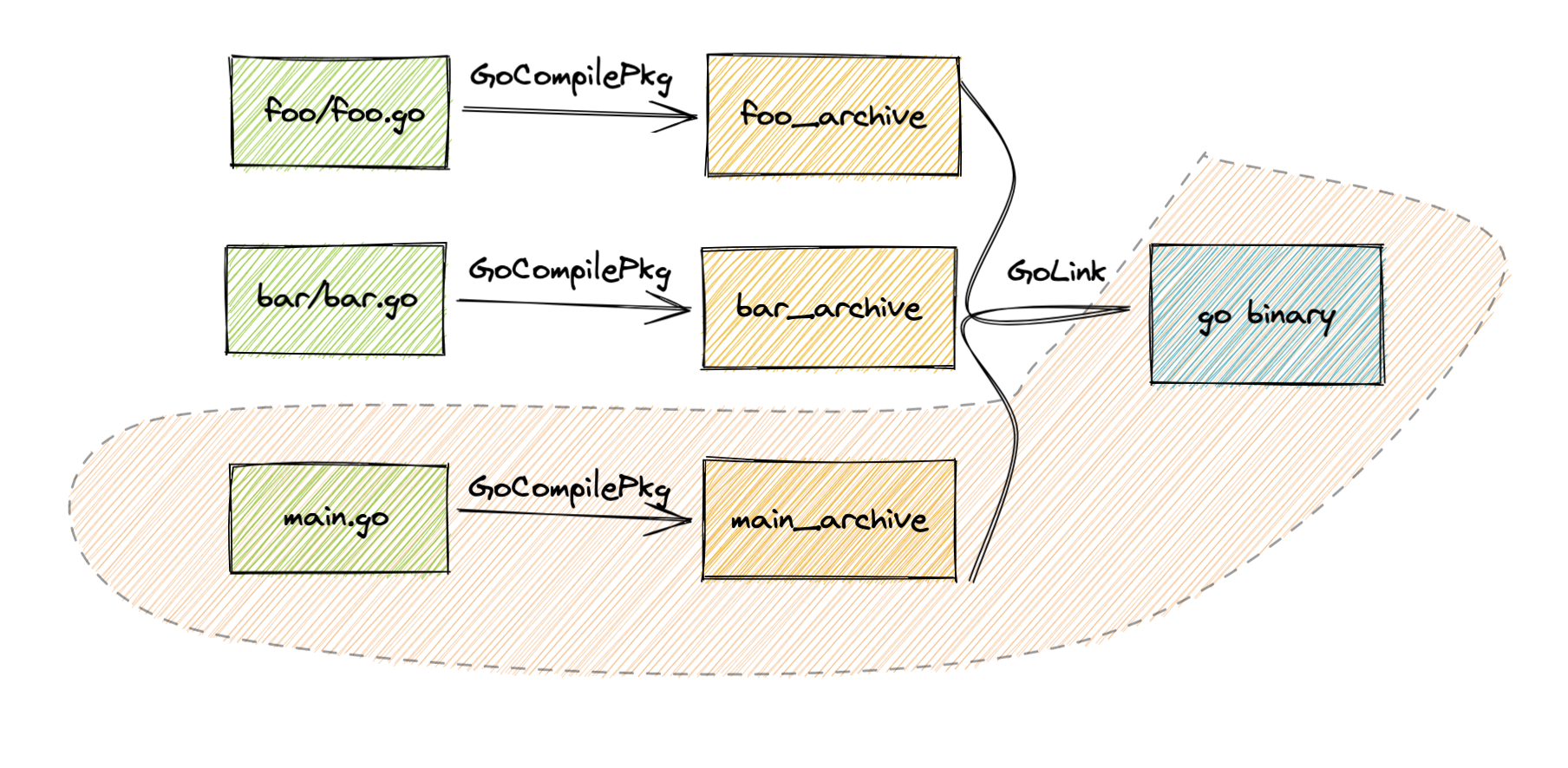
First of all, when main.go content was updated, then its SHA256 hash must also have changed.
So at the start of Bazel’s Execution phase, Bazel hashes the new files and stores the content of this new file in a new entry in CAS.
After that, GoCompilePkg action that consumes main.go will have its protobuf re-calculated, this time with a new input hash.
This would result in a new hash for this proto which could not be found in Action Cache.
This action would then get sent to the scheduler to get executed and produce a new main_archive to be stored in CAS.
This new result should also be recorded as a new entry in AC.
Similarly, GoLink action which takes main_archive as one of several inputs also has its hash recalculated.
It is then also sent to the scheduler and gets executed again, this time producing a new go binary artifact.
Both GoLink and go binary artifacts are newly stored in AC and CAS respectively.
For all other actions and artifacts in the workspace, they could be found from AC and CAS as their hashes have not changed. All of these are cached thus everything was effectively a no-op.
As you can see, leveraging hermetic action assumption, a Merkle-Tree Build Graph and it’s caching mechanism, Bazel was able to keep incremental builds minimal, accurate and fast.
Now that we have done a quick recap regarding how Bazel operates, in the next part in this series, we will dive into different layers of cache that Bazel uses to speed up your builds.



