Bazel Caching Explained (pt. 3): Repository Cache

I'm Son Luong Ngoc, a Solution Engineer at BuildBuddy. Previously I worked at Qarik / Booking.com / Lazada / Alibaba.
I am passionate about Developer Experience and the Reliability Culture in software development.
Author's Note
I started to write about Bazel's local-disk cache thinking that this is gona be a relatively simple, straightforward topic without much to discuss. Oh boy am I wrong.
The good part is that I don't often have to touch or to think about this caching layer on a day to day basis, which is great! Bazel did a great job at keeping this layer relatively boring, in a good way.
However, as I wrote down the details, I started to recall about the footgun I have encountered within the past years. A lot of them are not that obvious to new users, some of them could be quite confusing, or frustrating.
Therefore, I will intentionally highlight these footgun in their dedicated sections to warn readers about them.
I hope that these details will be fixed in the future, or at least there should be some guard rails surrounding them to improve
User Experience for newer folks adopting Bazel.
Local Disk Cache
Not to be confused with the option --disk_cache which is considered by Bazel to be an implementation of Remote Cache.
Eh.. What is what now?
It's confusing I know! We will re-visit Disk Cache when we get to Remote Cache in the future.
Bazel's local disk cache should be a lot simpler. These are things that Bazel stores on-disk by default without any additional configurations needed.
On a high level, there are 2 main things that Bazel cache locally on-disk:
Repository Cache
Action Cache (AC)
Today, we will be discussing Bazel's Repository Cache.
Repository Cache
Repository is generally known in Bazel ecosystem as a short-hand for External Repository
or, external dependencies. These are the packages that is often declared in your WORKSPACE file, often wrapped around using
a repository rule. Repository rules define how Bazel should prepare these external dependencies during loading-and-analysis
phase so that they can be consumed by usual build rules in execution phase
The 3 most primitive repository rules are:
local_repositoryis used to reference to a dependencies that is available on local machine via some directory path. The directory is used as-is by Bazel.git_repositoryis used to reference external dependencies that is available via a remote git repository, which will be shallow cloned by Bazel to prepare it for execution phase.http_archiveis used to download external dependencies as archives. These can be tar gzip, zip, zstd, etc... archives that is downloaded via HTTP(S) by Bazel. Before execution phase, Bazel would unpack these archives into a directories and use them as-is.
Out of the 3, http_archive is the most common, mostly thanks to our repository_cache.
In the http_archive rule, users are allowed to declare a SHA256 hash of the downloaded archive.
This helps ensuring that the final content of the archive is deterministic despite it's being downloaded over the network.
Here is how it work: When Bazel download the archive, it will immediately hash using SHA256 algorithm.
If there was no
sha256sumattribute declared in thehttp_archiverule, Bazel will simply print out the result SHA256 for user to copy paste it into the WORKSPACE file.If there was a
sha256sumattribute declared in thehttp_archiverule, it will validate the actual hash result against user's expected hash. In case the hash result does not match, Bazel will fail the build right away.
Additionally, if the result SHA256 hash matches with the expected SHA256 hash, Bazel will store the downloaded archive blob into a Content-Addressable Store (CAS) where the SHA256 hash is the key to the content. This store is the Repository Cache! Note that the Repository Cache CAS is different from the Build Artifact CAS that we mentioned in Part 1 of this blog series.
CAS is everywhere!
In subsequent Bazel run, before attempting to download the archive via HTTPS, Bazel will look up the user expected SHA256 hash to see if it exists in the Repository Cache.
If the archive exists in the Repository Cache, Bazel will reuse the content found in Repository Cache, unpack the content according to the declared format into the directory designated for that external dependency.
If the archive does not exists in the Repository Cache, Bazel will try to grab it from HTTP URLs declared in the WORKSPACE file and validate the result hash against expected hash. On success, Bazel writes the downloaded content into Repository Cache using the SHA256 hash as key / path.
So... the entire point of this Repository Cache is to save network bandwidth?
Yes! These archives could range anywhere between a single few KB binary to a zip file of the entire LLVM distribution. In another words, they could be massive and slow to download. Repository Cache helps save you the precious network round trips to download these.
Footgun no.1
Wait, what if I declare a false hash in my http_archive rule? Would that not result in Bazel blindly using a wrong archive cached in Repository Cache CAS?
Good eyes! Yes, Bazel's repository cache have a sharp edge that should be avoided.
Let's say you are currently using a kubectl binary via http_archive like this
http_archive(
name = "kubectl_1_24",
sha256 = "a4f011cc45666a8cc7857699e8d3609597f7364ffcf5dff089fc48c1704fd3b0",
urls = [
"https://internal-store.my-org.com/kubernetes-release/release/v1.24.0/bin/linux/amd64/kubectl.zip"
],
)
Then in the future, the newer version was added to the WORKSPACE file
http_archive(
name = "kubectl_1_24",
sha256 = "a4f011cc45666a8cc7857699e8d3609597f7364ffcf5dff089fc48c1704fd3b0",
urls = [
"https://internal-store.my-org.com/kubernetes-release/release/v1.24.0/bin/linux/amd64/kubectl.zip"
],
)
+http_archive(
+ name = "kubectl_1_25",
+ sha256 = "a4f011cc45666a8cc7857699e8d3609597f7364ffcf5dff089fc48c1704fd3b0",
+ urls = [
+ "https://internal-store.my-org.com/kubernetes-release/release/v1.25.0/bin/linux/amd64/kubectl.zip"
+ ],
+)
Note how the SHA256 hash was copied pasted from the older version and was not updated.
In this situation, it's very likely that kubectl_1_24 has already been cached in your Repository Cache CAS.
This would cause the declaration of kubectl_1_25 to silently re-using the kubectl_1_24's archive due to Bazel
using the same SHA256 hash when look up the content in Repository Cache.
However, this should fail in a fresh build where Repository Cache is empty.
Bazel would attempt to download kubectl_1_25 from the provided URL and found that the downloaded content
did not match the expected SHA256.
Repository Cache In Practice
So we have learned how Repository Cache works, but what problem does it solve in practice?
First, let's examine closely where is the repository cache is configured. Here is how it works on my MacBook Pro
> bazel info output_base
/private/var/tmp/_bazel_sngoc/f40639b59d6008c1b45f75138d187679
> bazel info install_base
/var/tmp/_bazel_sngoc/install/6b64cf61be23912f883b7ed0a05b85cf
> bazel info repository_cache
/var/tmp/_bazel_sngoc/cache/repos/v1
Observations:
Repository Cache is enabled by Bazel by default without needing any config.
The location of the cache directory is, by default, outside of output_base and install_base directories.
This means that the same repository cache could be shared accross multiple Bazel workspaces: different projects / git repositories that use Bazel. It can even be shared between different Bazel versions: i.e. between Bazel 4.x and 5.x.
After all, these are just representing the external dependencies downloads which should not be affected by the content of your workspace or the version of Bazel that is being used.
What this means is that the content of this cache will not be affected by bazel clean command and will be re-used
during a clean build attempt.
> bazel clean
INFO: Starting clean.
> du -sh /var/tmp/_bazel_sngoc/cache/repos/v1
1.5G /var/tmp/_bazel_sngoc/cache/repos/v1
> bazel clean --expunge
INFO: Starting clean.
> du -sh /var/tmp/_bazel_sngoc/cache/repos/v1
1.5G /var/tmp/_bazel_sngoc/cache/repos/v1
Another point to note is that repository_cache does not affect incremental build much.
At the beginning of a fresh build, Bazel will download and unpack the archive into the external
directory inside output_base.
# Do a fresh build but skip execution phase
> bazel build --nobuild //...
# Check the external repositories that were downloaded and unpack
> ls -al $(bazel info output_base)/external/
To help ensure the hermeticity of these external repositories, bazel use a <repo_name>.marker file
to store the hash combination between the repository rules definition and the downloaded archive's hash.
This hash will be used as part of the merkle tree calculation for Bazel to know when to re-execute the
repository rules to re-generate these external directories from downloaded archive.
# Find the unpacked repositories and their marker file
> find $(bazel info output_base)/external -maxdepth 1 -name '*remotejdk11_macos_aarch64*'
/private/var/tmp/_bazel_sngoc/052f439e991aecbc4a543d346a3f9f76/external/@remotejdk11_macos_aarch64_toolchain_config_repo.marker
/private/var/tmp/_bazel_sngoc/052f439e991aecbc4a543d346a3f9f76/external/remotejdk11_macos_aarch64_toolchain_config_repo
/private/var/tmp/_bazel_sngoc/052f439e991aecbc4a543d346a3f9f76/external/@remotejdk11_macos_aarch64.marker
/private/var/tmp/_bazel_sngoc/052f439e991aecbc4a543d346a3f9f76/external/remotejdk11_macos_aarch64
# Example content of a marker file
> cat $(bazel info output_base)/external/@remotejdk11_macos_aarch64.marker
2321b07d05bd5e4ba7681ece54d02d6156a5818f5260166a4f0b6bc6f60671ea
STARLARK_SEMANTICS 0
$MANAGED
FILE:@bazel_tools//tools/jdk:jdk.BUILD ef7168181a5ee2ce8a478c5192408ff01ae221457ee6000ba3c6812b4dba8246
# Use Bazel Query to find location of a repository
> bazel 2>/dev/null query --output=location '@remotejdk11_macos_aarch64//:all' | head -1
/private/var/tmp/_bazel_sngoc/052f439e991aecbc4a543d346a3f9f76/external/remotejdk11_macos_aarch64/BUILD.bazel:108:10: filegroup rule @remotejdk11_macos_aarch64//:bootclasspath
Therefore, at the beginning of an incremental build, Bazel would simply re-use the existing repositories
within the <output_base>/external/* directory and only rely on the Repository Cache when:
a. The repository was freshly added and not yet exist in the external directory.
b. The calculated hash of the repository does not match hash inside the marker file within <output_base>/external/*
In these cases, Bazel would re-fetch the archive from either the Repository Cache or HTTP(S) URLs and re-execute the Repository Rule to prepare it's content.
Second Footgun
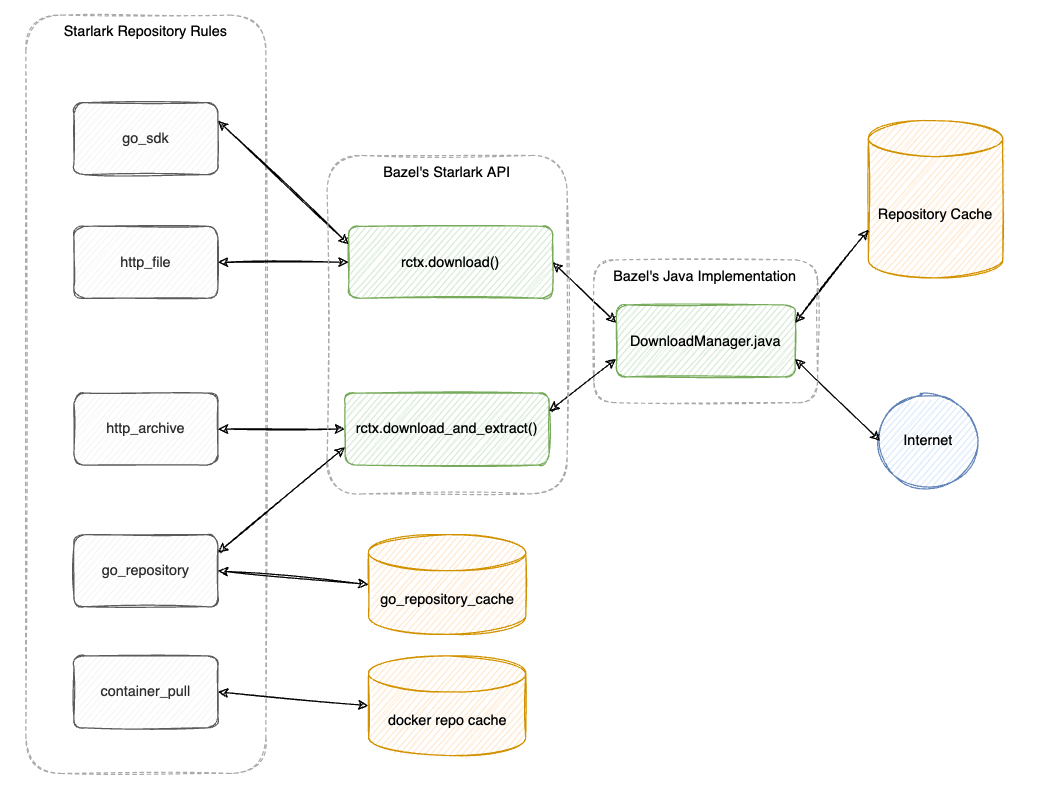
Another important point to make about Repository Cache is that: not everything repository rules are cached using the Repository Cache.
Repository Cache is a cache store that is specifically used as part of Bazel's DownloadManager.java class.
This class is used as the foundation for Bazel's Repository Context's rctx.download() and rctx.download_and_extract() implementations.
Only repository rules that make use of these starlark APIs would get cached by Repository Cache.
For examples:
http_archivemake use of these API within it's starlark implementationgo_repositorywould optionally use this when a URL is provided. By default, the Gazelle generatedgo_repositorytargets do NOT use Repository Cache but instead, provide a different custom caching option.rules_docker's
container_pulluses a custom puller binary to handle the downloads of container image. Therefore, it does not use repository cache but instead, provides it's own cache configuration
Conclusion
Bazel's Repository Cache is a part of Bazel's on-disk caching mechanism.
Most often, the Repository Cache is used to help bootstrapping a Bazel fresh build faster, reducing the pain of having to re-download the entire universe of external dependencies from scratch from Network.
It's enabled by default and user could customize it's location using the --repository_cache flag.



