Bazel in CI (Part 1): Commit Under Test

I'm Son Luong Ngoc, a Solution Engineer at BuildBuddy. Previously I worked at Qarik / Booking.com / Lazada / Alibaba.
I am passionate about Developer Experience and the Reliability Culture in software development.
Today I want to discuss a topic of different strategies in picking which commit to test against in CI, aka. choosing the commit under test or revision under test
Why should I care about this?
By picking the right commit in CI, you could solve several problems:
Improve testing accuracy
Improve testing speed (through better Bazel cache hit rates)
And by solving these, you should be able to improve iteration speed in the build and test portions of your DevX funnel
So let's get started.
A Git Recap
Before we start talking about this topic, we need to ensure that we are on the same page when it comes to some of the version control concepts. Since git seems to dominate the market share, I will be sticking with Git throughout this blog post, but the concepts could easily be applied to different VCS as well.
And because it would be incredibly boring to talk about these in text, I will try my best to draw these out.
Each code revision is called a commit. Each commit contains pointers to its parent commits. Typically, 1 commit has 1 parent.
A git branch is a marker/alias over a commit. This marker could be updated to move to whichever commit users choose. In today's workflow, we mostly see branches to be updated in an incremental forwarding fashion.
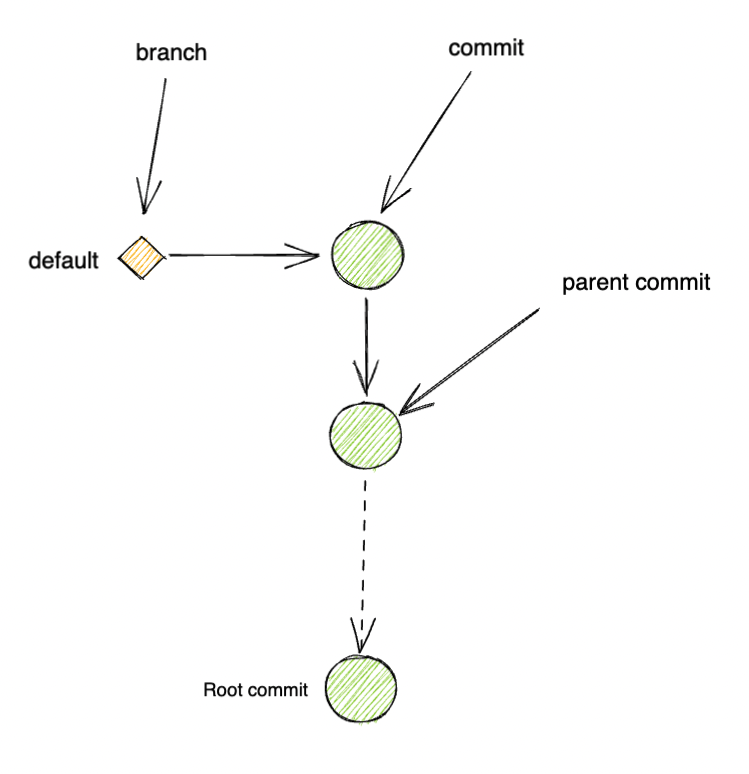
- A merge commit is a commit with multiple parents. Typically in today modern workflow, a merge commit is often used to combine (or intergrate) the results of 2 different diverged commits, or 2 different branches.
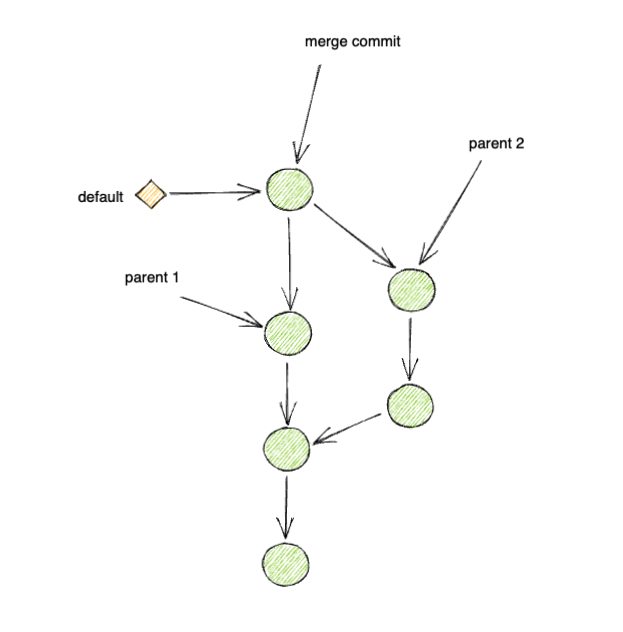
- A merge strategy is often referred to a uniformed strategy to combine the state of 2 branches in a repository. Popular strategies are 'Merge Fast-Forward', 'Merge Commit' and 'Fast-Forward only'.
For the sake of simplicity and better visualization, in this post I will be using the Merge Commit merge strategy in all the explanations.
But the concepts in this post should be applicable to w/e merge strategy you decided to use.
Additionally, I will be referring to the unit of changes in the repository as Change Request(CR). This is often known as Pull Request (Github, Bitbucket) and Merge Request (Gitlab).
These are changes to be introduced in a separate feature-branch, may include one or several new commits that are aimed to be merged into the default-branch, often being master or main or trunk in a monorepo.
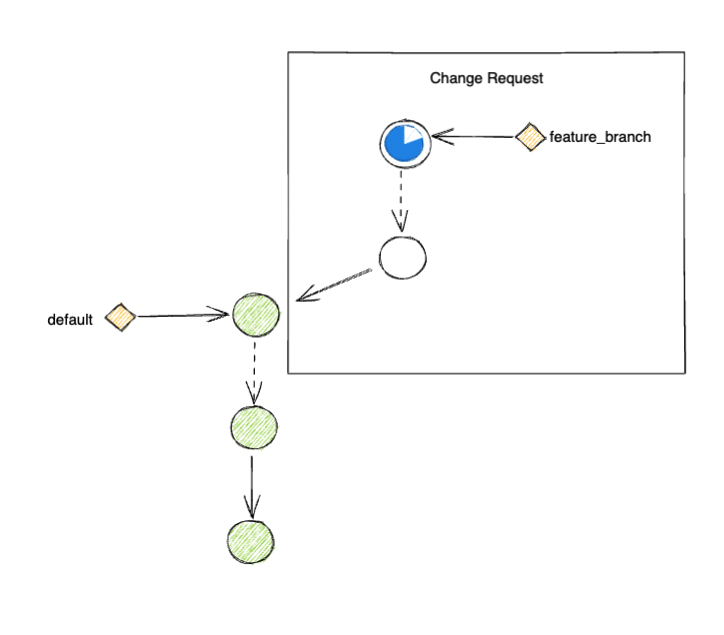
Testing a feature branch
So this is what a typical workflow would look like when you want to work on a new feature
Starting off, you have a monorepo with a default-branch.
Engineers would pick the latest commit from the default-branch to start creating new features.
Once the feature branch is pushed to trigger the CI system, we would test the branch and see if all checks passed.
So, what are the problems with this approach?
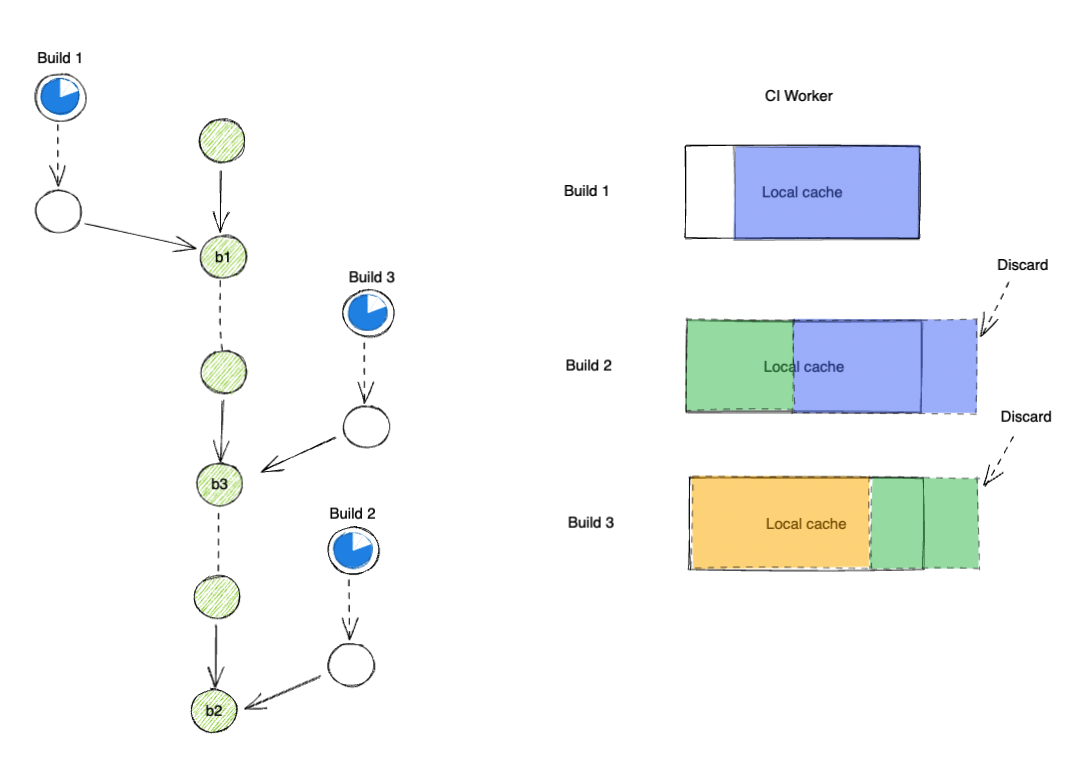
The main problem here is that your change set, from commit c1 to commit cN, is not being tested against default.
Since the time you have created c1 to cN, default has moved ahead with changes from different teams.
Instead of testing your feature against the latest changes in your company, you are testing against an older snapshot b1.
This means that during the time it takes you to develop cN, your teammates might have updated some API or shipped other conflict features that your current test could not help validate against.
As a result, your test results become less reliable.
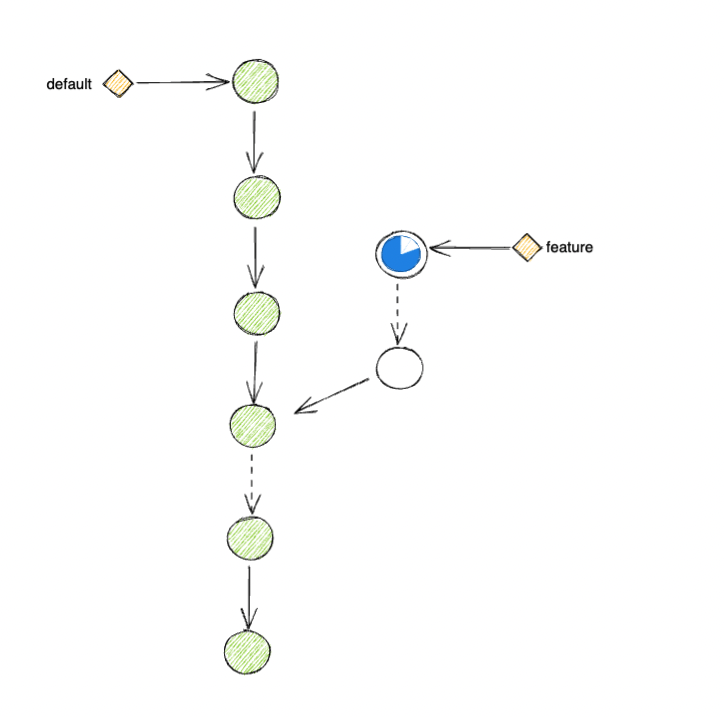
Another problem with this approach is that it affects Bazel caching on your CI worker negatively.
As we all know, Bazel makes heavy usages of local in-memory and disk caching.
Even with usages of a remote cache, AC and CAS entries needed to be downloaded to local disk first before they could be consumed.
And these downloads mean network transfer, thus they are slow.
Depending on how old b1 is relative to the latest revision your CI worker just tested against, the worker might have to re-download a significant amount of AC/CAS entries, slowing down your build and test.
In conclusion, by having an inconsistent base(or merge_base commit) for the commit under test, the local Bazel cache hit rate is reduced and thus slows down your build massively.
Testing against merge-result.
The solution to the problem above is quite simple: instead of testing against the HEAD commit of feature,
We could first perform a merge between feature and default and use the merge commit as the commit under test.
# Pre-merge test
> git fetch origin default feature
> git checkout default
> git merge feature
> bazel test --config=pre-merge //...
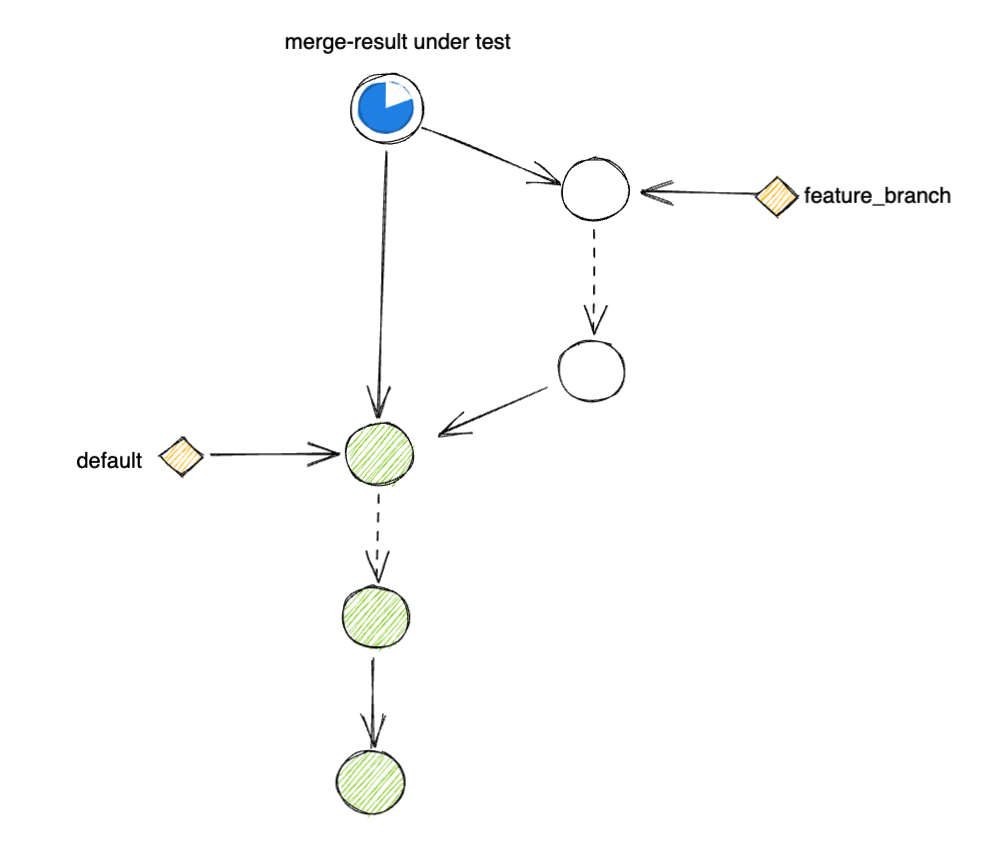
With performing a merge operation, we effectively include all the latest changes in default into our current checkout source code.
Effectively, the test result better reflects what the result would look like if you were to integrate the new feature into the rest of the monorepo at the moment of testing.
Moreover, because the base commit of the test is now always consistently being the latest commits in default with the incrementality guaranteed,
Bazel local cache on CI workers becomes a lot more predictable and highly consistent.
As the differences between tests executed on the same CI worker get narrower, the local cache hit rates improves, there should be a lot less need for network-based cache than before.
As a result, tests on CI should perform a lot faster and more accurately.
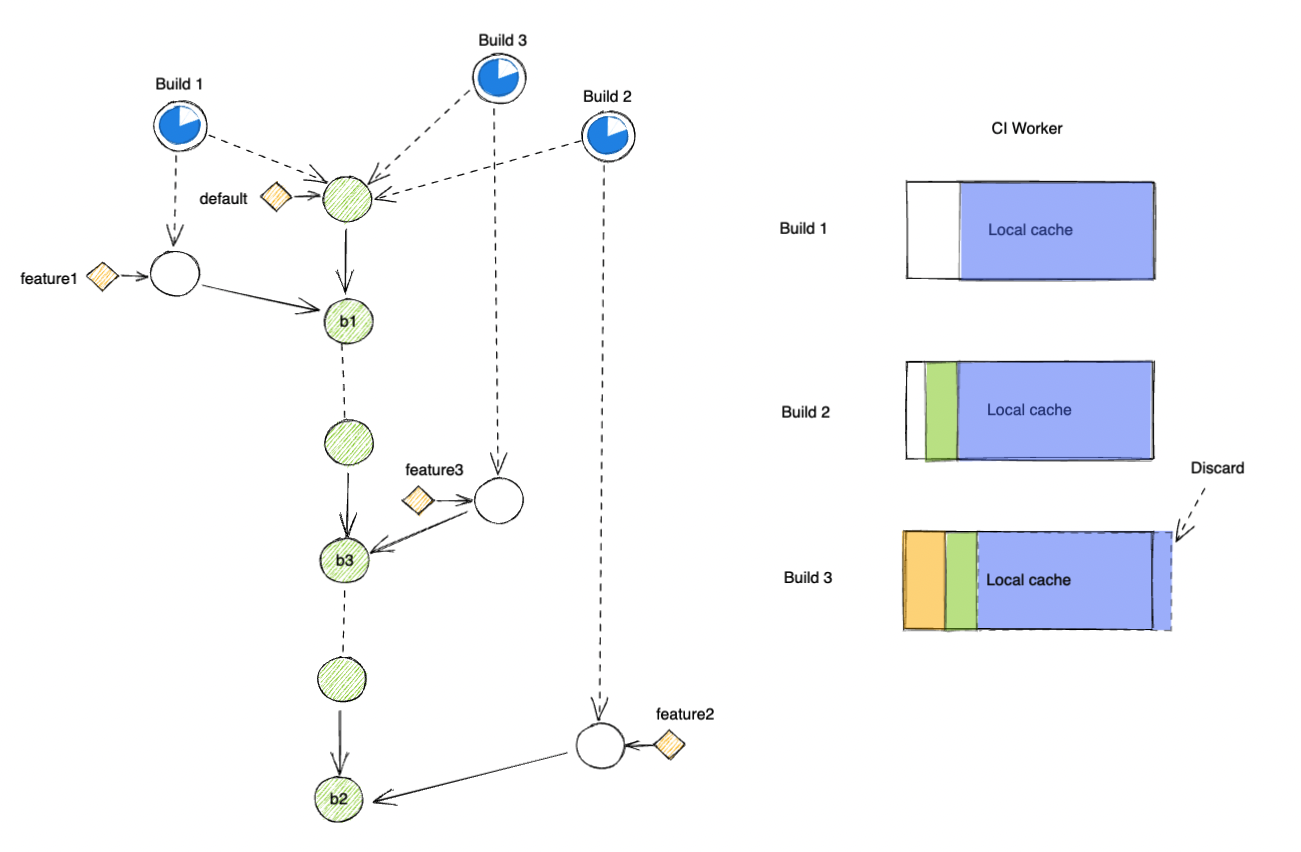
Testing against the merged result is supported by most modern CI services nowaday: Github, Gitlab, etc... But if you are using some self-hosted CI system, you could easily achieve similar results.
Wait a minute, I tried this out and my pipeline got worse
Somebody merged a bad change into the monorepo and now everything broke
Yes, with this setup, you add the latest commits on default to be a new dependency of your CI tests.
This would not be a problem if all commits in default are reliable, but in reality, things don't really work that way.
Mitigation Using stable Branch
A quick / cheap mitigation that would improve the reliability of your CI system is to... not use default branch as base.
Wait. Didn't you just tell me to use the
defaultbranch?🙃
Yes, but if your monorepo was moving really fast, the changes in default might not be that reliable yet, at least not after you have run all the post-merge tests.
So a common solution here is to separate the 2 definitions:
- Latest commit in
defaultbranch - Latest reliable commit in
defaultbranch
Where reliable here is measured using the post-merge test result.
Once you could separate these 2 definitions, you can annotate (2) with its own marker, a new branch stable.
Your post-merge process would look something like this:
# Post-merge test
> git fetch origin master
> git checkout master
> bazel test --config=post-merge //...
...
# Once test have passed, have CI system mark this latest commit
# by pushing it to the `stable` branch.
> git push origin HEAD:stable
Effectively, this would make stable a strict subset of default that only contains reliable change.
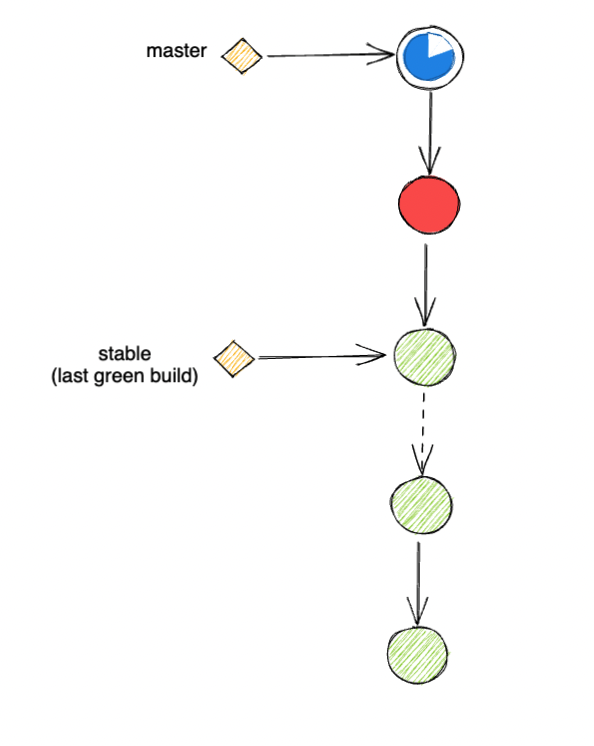
With this, you could perform the same merge strategy for your pre-merge test setup, but now, use stable instead of default
# Pre-merge test
> git fetch origin stable feature
> git checkout stable
> git merge feature
> bazel test --config=pre-merge //...
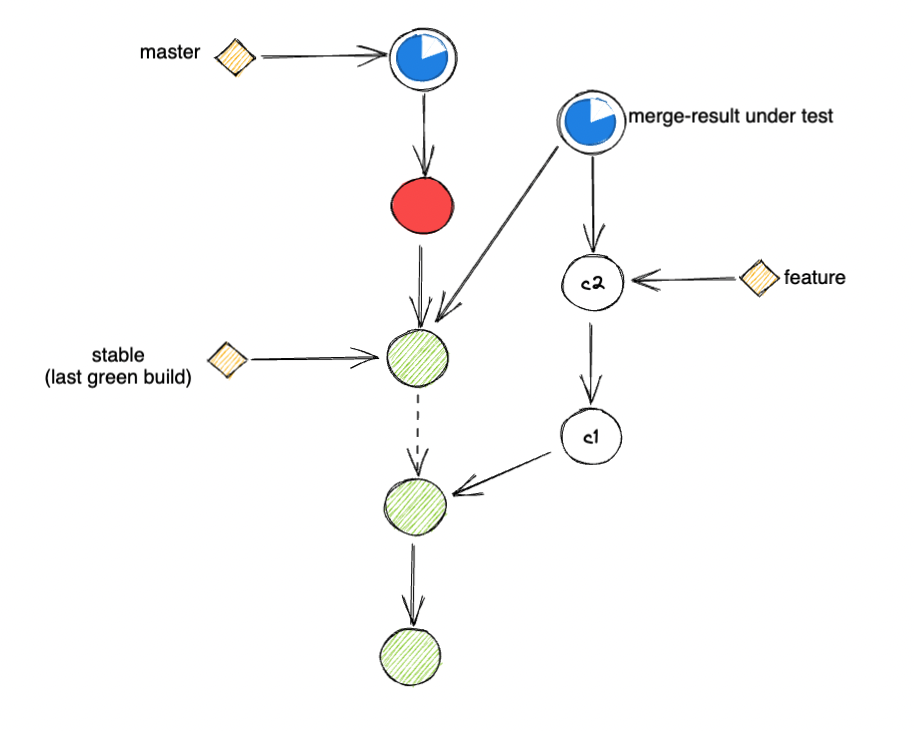
This helps shield your pre-merge CI tests against changes that are not yet verified by post-merge pipeline.
In a way, this helps improve the stability of your pre-merge pipelines a lot more.
However, it's simply a mitigation, stop-gap measure and does not address the root cause of the problem: changes landed in default could be unreliable.
Unreliable default Branch
If you simply allow CRs to get merged to default after your pre-merge tests successfully run, you might not be merging what you expected.
The problem is that the commit-under-test for your pre-merge pipeline, even with using a merge result commit, might not be the same with the result at actual merge time.
The reason behind this is between the test-execution starting time and the actual merge time, default branch could have been updated with other CRs merging.
This delay could happen when any of these happen:
Engineers wait for code review approvals after tests have passed.
Engineer shipping CR before End of Day and wait until the next work day to merge.
Pre-merge test pipeline was taking a long time
defaultbranch in a monorepo is updated rapidly.
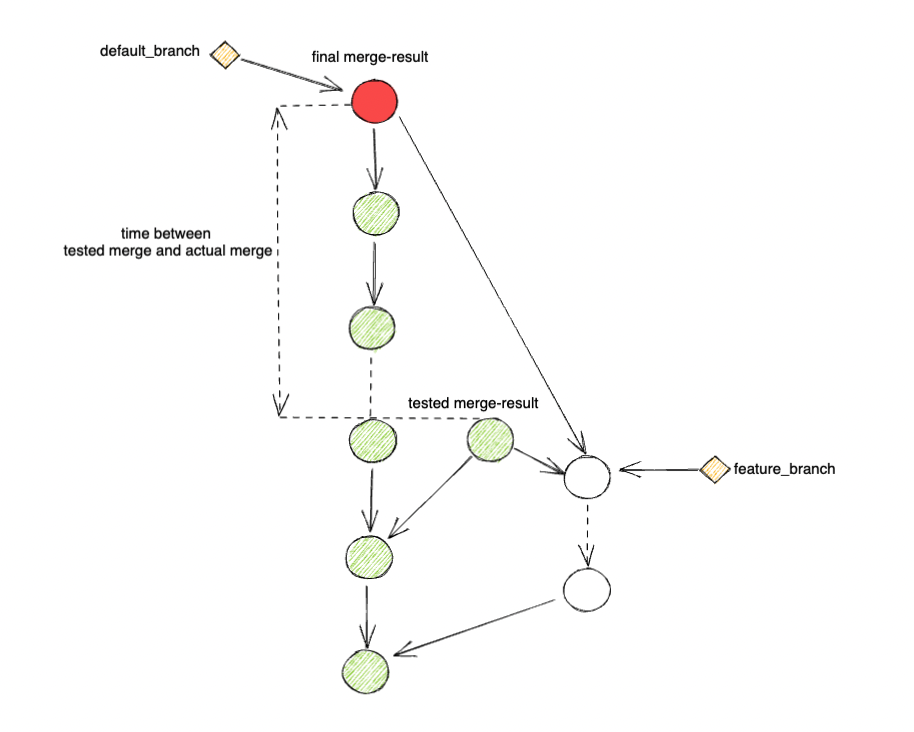
What this mean is that result of pre-merge test pipeline is unreliable when there is a lag between test time and merge time,
which in turn, causes the default branch to be unreliable.
With a sufficient count of engineers working close together in a small region of the code base, stepping on each others' toes is bound to happen.
Take this for an example:
# lib_a.go
var a = 0
# lib_b.go
var b = 0
# lib_test.go
func TestNum(t *testing.T) {
sum := a + b
if sum > 10 {
t.Error("a is more than 10")
}
}
# CR 1 updates lib_a.go
- var a = 0
+ var a = 5
# CR 2 updates lib_b.go
- var b = 0
+ var b = 6
Both CR1 and CR2 passed the
pre-mergepipeline as in their own pipeline,sumvariable has the value of5or6respectively.When CR1 landed on the
defaultbranch,sumindefaultbranch test is5which is good.When CR2 landed onto the
defaultbranch,sumindefaultbranch test is11which causespost-mergepipeline to go red.
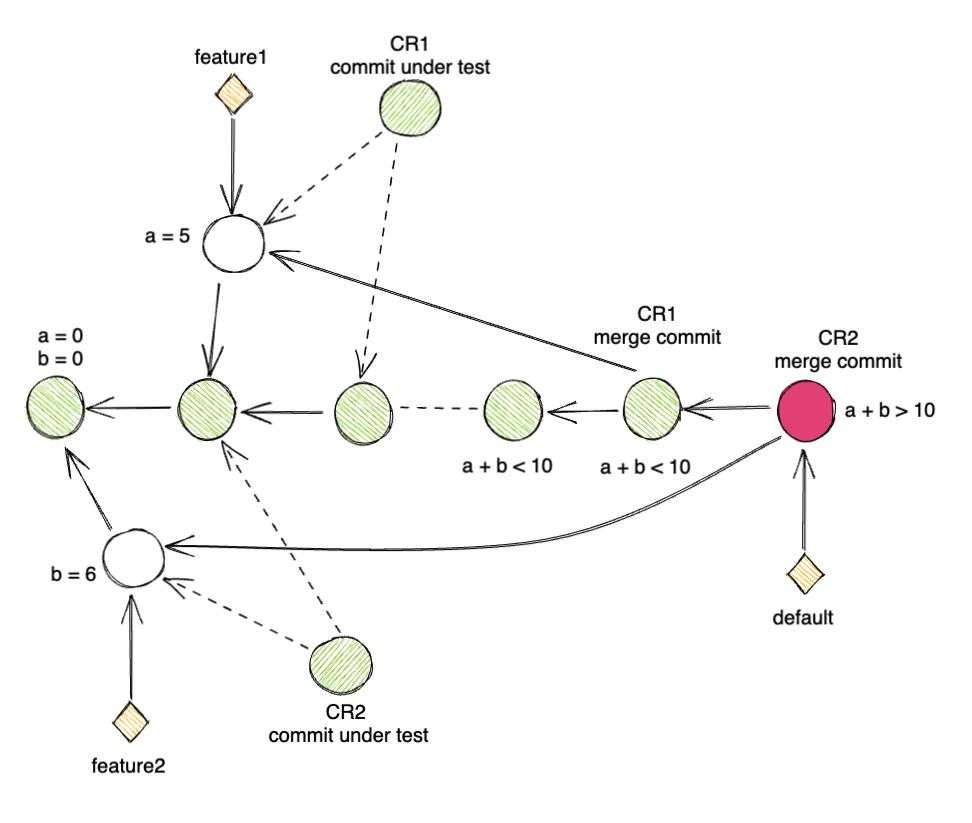
Note how there is no merge conflict between CR1 and CR2 as they modify 2 different files. The broken is a result of the CR2 being tested with 1 base commit while being merge against another commit.
So what is wrong here and how do we fix it?
What is missing is to ensure the content of default branch after the actual merge to be consistent with the content of commit-under-test. For this to happen, we need to lock default from being updated for the duration of test execution.
To achieve this lock mechanism, we need to introduce a new concept called the Merge Queue and couple with it is Merge Queue Test Pipeline.
Merge Queue
A merge queue simply queues up CRs to be merged to default branch.
It ensures that CRs are merged in the order that they enter the queue.
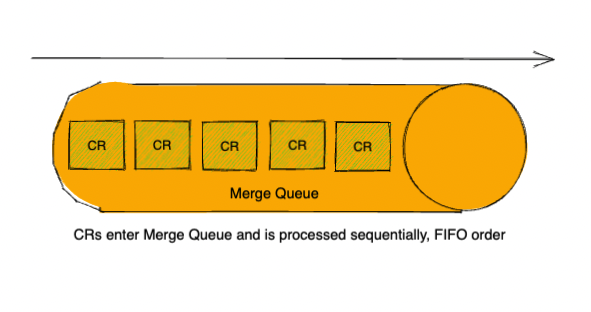
Thanks to this ordering, during queue time,
we could execute a test pipeline against a hypothetical merge result commit that better reflects the state of default after the merge happens.
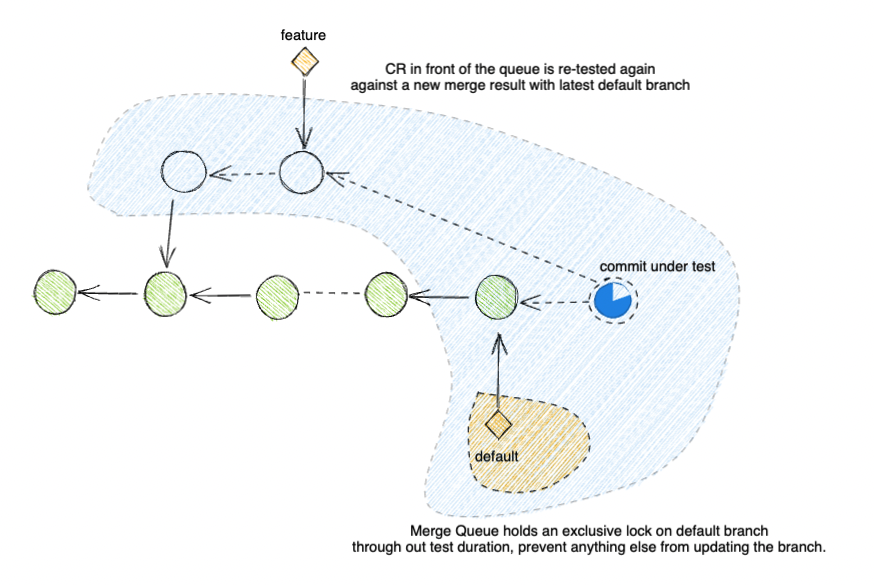
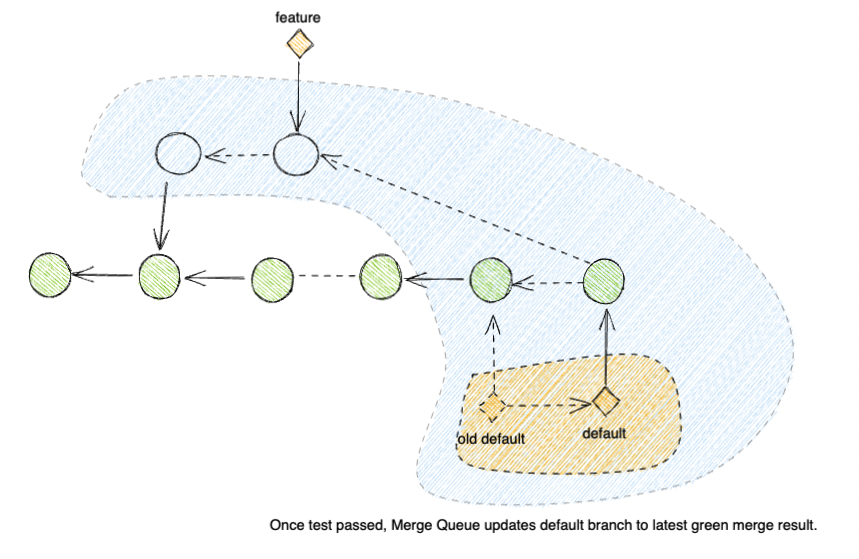
Since CRs must enter the queue before landing onto default, we don't have to worry about default being updated during the test duration.
The queue also helps guarantee that we merge happen automatically right after test have passed, so we don't need to worry about the lag between test time and when human engineers return after a long vacation.
Don't worry, you can still enjoy your vacation, you just need to enqueue and retest your CR after coming back.
To reuse the example above:
Both CR1 and CR2 passed the
pre-mergepipeline as in their own pipeline,sumvariable has the value of5or6respectively.User1 enqueued CR1
User2 enqueued CR2
Merge Queue test CR1 using the merge result between CR1 and
default.sum == 5is calculated, test passed and CR1 landed todefault.Merge Queue test CR2 using the merge result between CR2 and the updated
default.sum == 11is calculated, test failed and CR2 is marked as fail for User2 to iterate upon.
So by using Merge Queue backed by CI tests, the merge operation result is a lot more reliable.
Wait, all these seem... heavy.
Wouldn't requiring a pipeline to pass in the queue cause the queue to move very slowly?
This means that it would take a lot longer than before for my change to land onto
default?
Yes, it would take longer.
We are employing more thorough checks to ensure that default is more reliable for everyone.
No, it does not need to be a lot longer.
Thanks to Bazel and merge-result testing, the tests should execute relatively fast.
Moreover, thanks to default being more reliable, your test results are more reliable
which in turn should reduce test retry counts.
So overall things should not be that slow.
Yeah but if there are a lot of people in queue, I will have to wait for all of them for my turn to merge.
This means my test is scheduled for later right?
The total time between me enqueuing my CR until it successfully landed would scale up with the queue size?
Good observation!
Yes, but there is a trick to reduce these test-queuing times.
It's called Speculative Pipeline Execution.
Speculative Pipeline Execution
There are 2 properties of the Merge Queue that we could leverage:
First, only CRs which have passed the
pre-mergetest could enter the queue. Although we are running tests within the queue, we still want to keep runningpre-mergetests before enqueuing CRs. The purpose ofpre-mergetests is to provide engineers with semi-reliable test results to iterate against quickly. So running tests against a snapshot ofdefaultis acceptable in this case.Second, the order of CRs being merged into
defaultis known, thanks to the queue being First In First Out.
From (1), we could assume, to a reasonable degree, that if a CR manage to pass pre-merge test pipeline to enter the queue,
it's highly likely that it would also pass the Merge Queue test pipeline (Note that this is NOT 100% guaranteed).
Combining with (2), we have a reasonable hypothesis to speculate on what the state of default branch would be at the time of merge for each CR in the queue.
Change Request and speculate merge result
CR1: merge(CR1 + default)
CR2: merge(CR2 + CR1 + default)
CR3: merge(CR3 + CR2 + CR1 + default)
...
CRN: merge(CRN + ... + CR3 + CR2 + CR1 + default)
So to speed up the Merge Queue, we could save the time it would take to wait in turn to start a Merge Queue pipeline: instead of waiting until you become the CR in front of the queue to kick off the pipeline, simply start the pipeline against the speculated merge commit when a CR enter the queue.
Change Request and speculate test pipeline
CR1: test(merge(CR1 + default))
CR2: test(merge(CR2 + CR1 + default))
CR3: test(merge(CR3 + CR2 + CR1 + default))
...
CRN: test(merge(CRN + ... + CR3 + CR2 + CR1 + default))
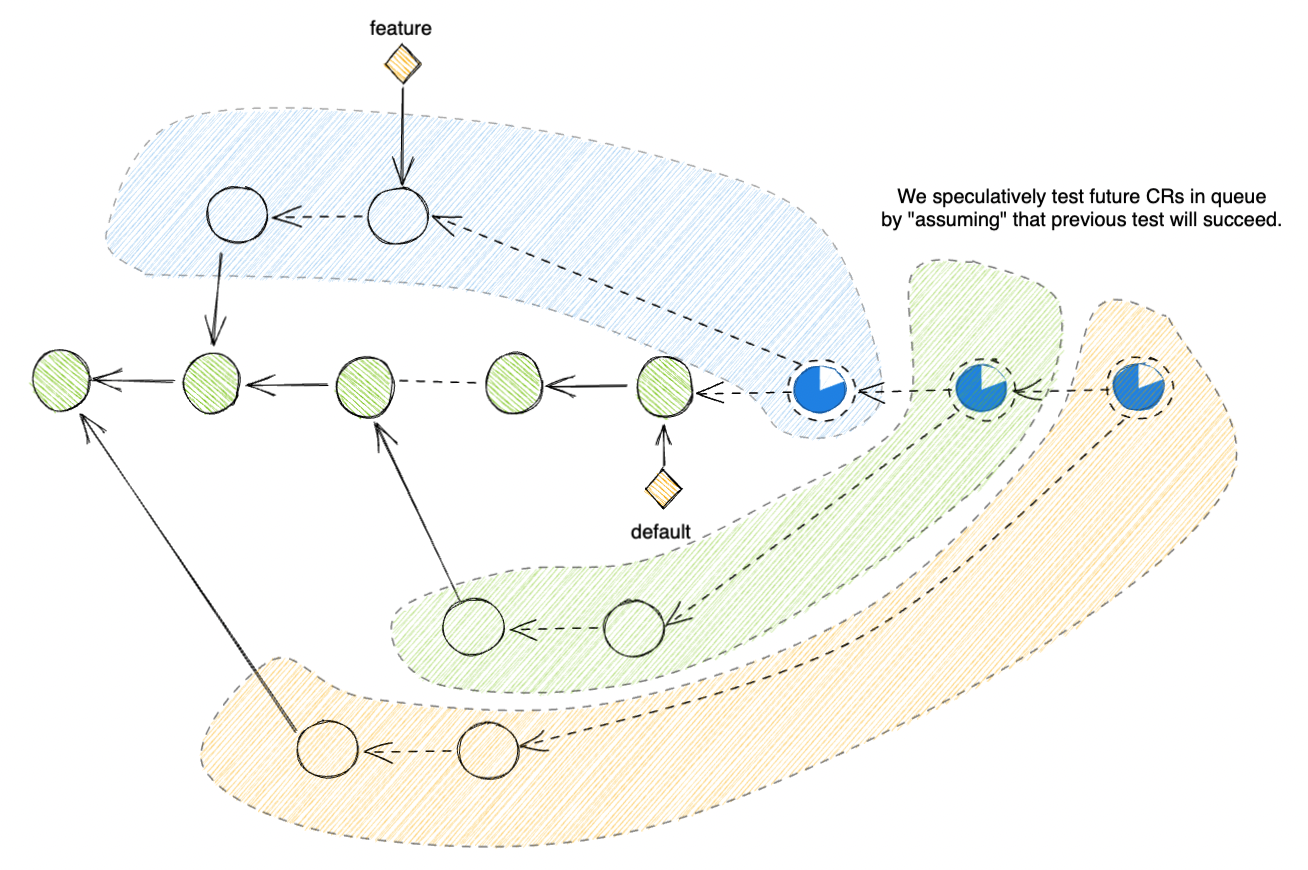
Let's take a look at an example on how this would help speed up the queue:
CR1:
- Test Time: 60s
- Merge Time: 1s
CR2:
- Test Time: 90s
- Merge Time: 1s
CR3:
- Test Time: 1800s
- Merge Time: 1s
Assuming CR1 and CR2 and CR3 all enter the queue at once in that order, the time it would take CR3 to land in default would be:
# CR1
# -->
#
# CR2
# --->
#
# CR3
# ------>
time_to_land(CR3) = 60 + 1 + 90 + 1 + 180 + 1
= 333 seconds
= 5 minutes 33 seconds
Now let's see what would happen with speculative execution
# CR1
# -->
#
# CR2
# --->
#
# CR3
# ------>
time_to_land(CR3) = max(60, 90, 180) + 1 + 1 + 1
= 180 + 1 + 1 + 1
= 183 seconds
= 3 minutes 33 seconds
Speculative pipeline execution allows Merge Queue Test Pipelines for each CR in queues to be executed in parallel and thus, speed up the time it takes for CR to land.
Wait, what happens when the speculation goes wrong?
When a previous CR in the queue is ejected from the queue instead of landing on default, presumably because of a test fail or user manual cancelation, we have to re-do the speculation for the rest of the queue.
So in the worst case scenario, we have to re-execute the speculation multiple times for multiple CRs failing.
Let's re-use the above example, except this time, let's assume CR1 and CR2 would fail and CR3 would succeed.
# CR1 (first attempt - failed)
# --X
#
# CR2 (first attempt - canceled)
# --X
#
# CR3 (first attempt - canceled)
# --X
#
# CR2 (second attempt - failed)
# ---X
#
# CR3 (second attempt - canceled)
# ---X
#
# CR3 (third attempt - succeed)
# ------>
time_to_land(CR3) = 60 + 1 + 90 + 1 + 180 + 1
= 333 seconds
= 5 minutes 33 seconds
So in the worst case scenario, we would land CR3 in the same duration as we don't speculate anything. The tradeoff here is that we waste a lot of compute resources to speculate test results of these CRs.
One way to help save computation would be to only speculate for a limited number of CRs in front of the queue instead of for everything inside the queue. This number could be 5, or 10, or 20, depending on the rate of change in your monorepo and how likely it is for a CR to get ejected. Or it could depend on how conservative you are in using compute resources for CI.
Either way, measurements and iterations is the way to go about deciding these numbers.
Conclusion
As demonstrated, a healthy CI setup requires close integration with VCS of choice. The only way to get an accurate CI result is to understand and leverage version control so you could accurately specify the right version to test against. To achieve a high velocity DevX platform, an organization would need to have close integration between different components in the DevX Funnel to unlock more capabilities.
A system with well glued CI and VCS allows you to test faster with higher accuracy. Bazel compliments very well in such a highly integrated setup as it empowers your CI system with different levels of caching, including in-memory cache. With higher test accuracy, Bazel speeds up thanks to improved cache hit, which in turn speeds up overall CI execution and enables faster merge. This will be a recurring theme in future blog posts as we will repeatedly see how CodeSearch, IDE, VCS, CI, CD are supposed to be highly tuned and aware of each other to create a high quality DevX platform.
At scale, there are more techniques that could help speed up the speed of CR being merged into default branch: batching up changes, post-merge bisection tests to auto-revert, using Machine Learning to predict safe CRs, failing tests, etc... I decided not to discuss these for the time being as they often come with some tradeoffs which could be business specific. My advice is generally: measure, identify pain points and solve the pain points. Don't let a beautiful solution drive the actions, start with the ugly problem first.
Final note: these concepts could be adopted incrementally for various different organizations with different VCS and CI service providers. Not being a lift-and-shift means less risks for orgs to adopt and experience the benefits of these strategies almost immediately.
So what are you waiting for?


